MITRE ATT&CK for AWS: Understanding Tactics, Detection, and Mitigation
The MITRE ATT&CK framework is a globally recognized knowledge base of adversary tactics and techniques that provides a structured model for cyber threats. In the context of cloud computing (such as Amazon Web Services),ATT&CK is extremely useful for mapping out potential attack paths and strengthening AWS security. By aligning AWS security monitoring and incident response with ATT&CK tactics, security teams gain a common language to describe threats and can ensure coverage for each phase of an attack lifecycle. This helps SOC analysts and cloud security engineers systematically detect malicious behavior and respond effectively, using AWS’s native tools and logdata.
Mapping AWS security monitoring to MITRE ATT&CK provides a structured way to detect and mitigate threats across all attack stages. By leveraging CloudTrail, GuardDuty, Flow Logs, IAM policies, and automated alerts, organizations can detect, contain, and mitigate AWS-specific attacks before they cause serious damage.
MITRE ATT&CK for AWS: Understanding Tactics, Detection, and Mitigation
Introduction
The MITRE ATT&CK framework is a globally recognized knowledge base ofadversary tactics and techniques that provides a structured model for cyberthreats. In the context of cloud computing (such as Amazon Web Services),ATT&CK is extremely useful for mapping out potential attack paths andstrengthening AWS security. By aligning AWS security monitoring and incidentresponse with ATT&CK tactics, security teams gain a common language todescribe threats and can ensure coverage for each phase of an attack lifecycle.This helps SOC analysts and cloud security engineers systematically detectmalicious behavior and respond effectively, using AWS’s native tools and logdata.
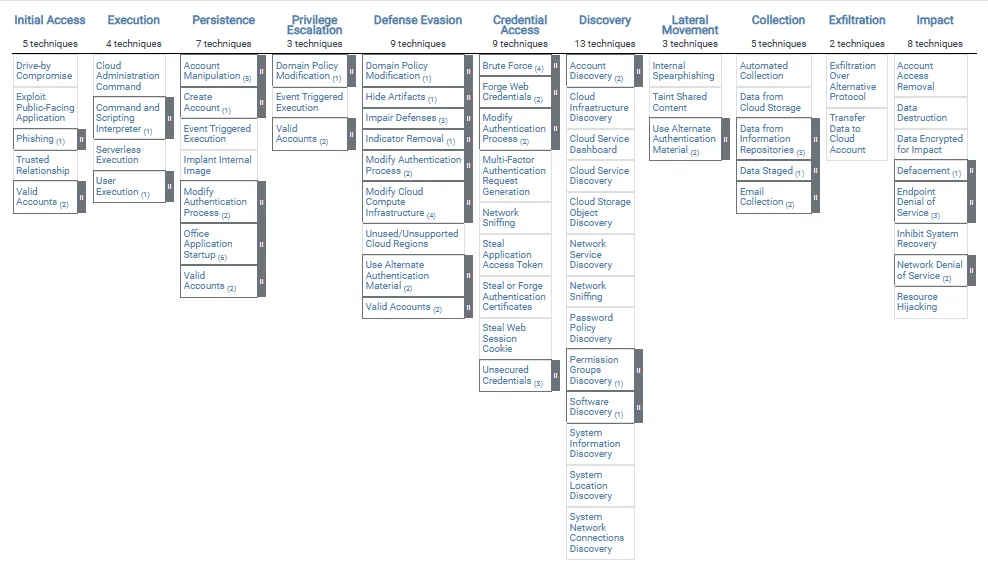
In this blog, we break down each MITRE ATT&CK tactic from InitialAccess through Impact as it applies to AWS. For each tactic, we highlightrelevant AWS services and log sources to monitor (e.g., AWS CloudTrail, AmazonGuardDuty, VPC Flow Logs), give examples of log queries using AWS-native tools(CloudWatch Logs Insights, Athena, Security Hub), discuss practical detectionstrategies, and recommend mitigation best practices. This structured approachwill help you map AWS-specific threats to the ATT&CK framework andimplement defenses for each stage of an attack.
Initial Access
Overview: The Initial Access tactic covers how an adversary first gainsentry into your AWS environment. In AWS, this often occurs via compromisedcredentials or exploitation of publicly exposed cloud services. For example, anattacker might obtain valid AWS access keys from a leaked source (GitHub,config files, etc.) or exploit a vulnerable application hosted on EC2 to get afoothold. According to MITRE’s cloud matrix, adversaries commonly “gainaccess to cloud resources through compromised accounts or exploitingpublic-facing services”. In practice, this could mean using stolen IAM usercredentials, guessing a weak console password, or abusing a misconfiguredservice (such as an open S3 bucket or exposed database) to break in.
AWS Services/Logs to Monitor:
AWS CloudTrail – Capture all login attempts and API calls. Monitor ConsoleLogin events (for web console sign-ins) and AWS STS events (e.g. AssumeRole) for suspicious activity. CloudTrail is the primary data source for detecting unauthorized access to AWS APIs. It logs both successful and failed authentication events, making it invaluable for spotting brute-force login attempts or use of stolen keys.
Amazon GuardDuty – GuardDuty continuously analyzes CloudTrail logs, VPC Flow Logs, and DNS logs for threats. It can detect anomalous access patterns, such as an InitialAccess finding when an adversary tries to establish access to your account (GuardDuty finding format - Amazon GuardDuty). For example, GuardDuty will alert on brute-force attacks against EC2 instances (SSH/RDP) or usage of credentials from an unusual location.
AWS CloudWatch Logs & Events – CloudTrail logs can be delivered to CloudWatch Logs, where CloudWatch Logs Insights queries or metric filters can trigger alarms on suspicious events (e.g., multiple failed logins). CloudWatch Events (EventBridge) can also trigger on specific CloudTrail events like ConsoleLogin or AuthorizeSecurityGroupIngress.
VPC Flow Logs – If the initial access is via network intrusion (e.g., exploiting an open port on an EC2 instance), VPC Flow Logs help detect unusual inbound connections. For instance, repeated connection attempts from a single external IP to many ports could indicate scanning or brute force (GuardDuty has Recon findings for port scans (GuardDuty finding format - Amazon GuardDuty)).
Detection Strategies:
Anomalous Console Logins: Look for unusual login patterns. Multiple failed ConsoleLogin events followed by a success may indicate a guessed password. Also, logins from foreign locations or atypical user agents (e.g., script/CLI vs. usual browser) are red flags. GuardDuty’s UnauthorizedAccess findings (e.g., “IAMUser/AnomalousIPCaller”) alert when an API call originates from an IP address not previously seen for your account or known malicious IP ranges.
Use of Stolen Keys: Monitor CloudTrail for API activity by IAM users or roles at odd times or from new IPs. If an access key that has been unused for months suddenly starts making API calls, especially from an unfamiliar IP address, this could be an attacker. GuardDuty’s CredentialAccess or InitialAccess categories detect patterns like usage of credentials from an atypical geolocation (GuardDuty finding format - Amazon GuardDuty) (GuardDuty finding format - Amazon GuardDuty).
Brute Force on EC2: If you have EC2 instances running SSH/RDP, enable GuardDuty – it will detect brute-force attacks (e.g., UnauthorizedAccess:EC2/SSHBruteForce). Even without GuardDuty, you can analyze VPC Flow Logs for repeated connection attempts. For example, numerous flows from a single external IP to port 22 of an EC2 instance may indicate an SSH brute force attempt.
Mitigation and Best Practices:
Multi-Factor Authentication (MFA): Enforce MFA on all interactive IAM users, especially for root and privileged accounts. MFA greatly reduces the likelihood of account compromise via stolen passwords. Consider AWS SSO (IAM Identity Center) or external IdPs to centralize authentication with MFA.
Least Privilege Credentials: Avoid long-lived IAM user credentials when possible – use IAM roles and temporary credentials. Remove unused IAM users and keys. This limits the opportunity for an attacker to find valid credentials and also limits what any single credential can access.
Secure Public Endpoints: Regularly audit and patch internet-facing AWS resources (EC2, ALB, API Gateway, etc.). Use AWS WAF to protect web applications and AWS Shield to mitigate DDoS, reducing the risk of exploitation of vulnerabilities for initial entry.
Credential Hygiene: Rotate access keys regularly and never embed secrets in code or public repositories. Use AWS Secrets Manager or Parameter Store to manage secrets. Additionally, monitor open-source for leaked credentials related to your organization. AWS CloudTrail can integrate with AWS IAM Access Analyzer to report publicly exposed keys.
GuardRails: Implement AWS Organizations Service Control Policies (SCPs) to restrict actions like creating new IAM users or disabling security features (where feasible for your environment). This can prevent an attacker with a stolen low-privilege account from performing high-impact initial access activities.
Execution
Overview: Once inside, an attacker will attempt to execute code or commandsto further their objectives. In AWS, Execution can take many forms.Adversaries might run malware or scripts on a compromised EC2 instance, invokeAWS Lambda functions or AWS Systems Manager (SSM) commands, or spin up newcompute resources to run malicious code. According to AWS, this stage covers attemptsto “run or already run malicious code to explore the AWS environment, orsteal data” (GuardDutyfinding format - Amazon GuardDuty). For example, an attacker with AWSaccess might launch a new EC2 instance to run a malicious container, or use SSMto execute system commands on an existing instance. They could also deploy abackdoor Lambda function that runs on a schedule. All these actions fall underExecution in the ATT&CK framework.
AWS Services/Logs to Monitor:
AWS CloudTrail – Monitor for API calls that indicate code execution or resource creation. Examples: RunInstances (launching a new EC2 instance), StartInstances (starting a stopped instance), Invoke* (invoking a Lambda or Step Function), SendCommand or StartSession (SSM executing commands on EC2), and AWS Glue or ECS APIs that start jobs or tasks. These events may signal an attacker trying to run unauthorized workloads. CloudTrail provides visibility into what was executed and by whom.
Amazon CloudWatch Logs – If EC2 instances or Lambda functions are configured to send logs to CloudWatch, those logs can contain indicators of malicious code execution (e.g., error messages from a malware process, or unusual application log entries). CloudWatch Logs Insights can search application logs for known IoC patterns or suspicious process names if the data is available.
Amazon GuardDuty – GuardDuty’s Execution threat purpose will flag attempts to run malicious code in your AWS environment (GuardDuty finding format - Amazon GuardDuty). While GuardDuty doesn’t see inside instances, it infers execution from behavior. For example, GuardDuty might generate a CryptoCurrency finding (like “EC2 instance behaving as a Bitcoin miner”) which indicates unauthorized code running for cryptomining. Another example is a “Execution:EC2/CommandAndControl” if known C2 traffic is detected (blurring into the C2 tactic). GuardDuty also watches for API calls patterns that suggest execution of recon tools or exploit scripts.
VPC Flow Logs – After code executes, it often results in network activity (for example, malware scanning the network or connecting to external C2 servers). VPC Flow Logs can catch unusual outbound connections from an instance that might indicate malicious code execution effects (e.g., a normally quiet server starting to make many outbound connections).
AWS Security Hub – Security Hub can aggregate findings from services like GuardDuty, AWS Inspector, or EDR solutions (if integrated). For instance, if AWS Inspector or an EDR detects malware on an EC2 instance, it would appear as a finding in Security Hub, aligned to Execution and other tactics.
Detection Strategies:
CloudTrail Anomaly Detection: Identify new types of API calls by users/roles. For example, if an IAM role that historically only read S3 data suddenly issues a RunInstances or Lambda Invoke API call, that’s suspicious. Use CloudTrail logs to baseline typical operations and alert on out-of-profile actions. A query can help: “Show any IAM user who has invoked an EC2 RunInstances API for the first time.”
Multiple Resource Creations: Attackers might create many resources for malicious tasks (e.g., launch 20 EC2 instances for a botnet or crypto mining). CloudTrail events like RunInstances can be counted per user. If a typically low-usage account spawns numerous instances or Lambda invocations in a short period, it could indicate execution of unauthorized workloads. AWS CloudWatch Events could trigger a Lambda to alert or shut down instances if a threshold is exceeded (automated containment).
GuardDuty Alerts: Rely on GuardDuty for known malicious execution patterns. For example, a CryptoCurrency:EC2/BitcoinTool finding means an EC2 instance is likely running cryptocurrency mining software (GuardDuty finding format - Amazon GuardDuty). This is a strong sign that someone executed unauthorized code on that instance (often through exploitation). Similarly, a Behavior:EC2/NetworkPortUnusual finding might indicate an instance started communicating on a port it never used before (possibly due to malicious code starting a new service) (GuardDuty finding format - Amazon GuardDuty). SOC analysts should treat such findings as execution of malicious payloads and investigate the timeline via CloudTrail (to see how that instance was accessed or modified).
OS-level Monitoring: If you have host-based monitoring (an agent or EDR on EC2 instances), leverage it for execution indicators: processes launching with strange names, new scheduled tasks (cron jobs) created, or scripts running from tmp directories. While not AWS-native, integrating these logs into CloudWatch or Security Hub can enrich detection. AWS Systems Manager’s Inventory or AWS Config can also detect if software installations change on an instance.
Code Build/Deploy Abuse: Watch for abuse of CI/CD services as an execution vector. An attacker with access might use AWS CodeBuild or CodePipeline to run arbitrary build commands. CloudTrail logs for CodeBuild project start or CodePipeline execution could be reviewed, especially if they trigger out-of-band.
Mitigation and Best Practices:
Principle of Least Privilege: Restrict permissions so that only appropriate roles can execute critical actions. For example, developers might not need permission to launch EC2 instances or invoke arbitrary Lambda functions in production. Use IAM policies to limit who can use services that execute code (EC2, Lambda, ECS, SSM). This way, even if an attacker gains credentials, they cannot easily run new code.
Service Control Policies (SCPs): On an organizational level, use SCPs to prevent certain risky actions in accounts entirely. If your organization never uses, say, AWS Lambda in Account X, an SCP could deny lambda:InvokeFunction and lambda:CreateFunction in that account. This provides an additional guardrail against execution of unauthorized compute.
Logging and Alerting on Changes: Enable CloudTrail logging for all regions and consider AWS Config to track changes in resource states (like EC2 instance state changes). Configure CloudWatch Alarms or Security Hub insights for events like an unusual spike in EC2 launches or sudden invocation of rarely used services. Timely alerts can allow you to stop malicious code before it causes damage (e.g., by terminating instances an attacker spun up).
Isolation and Network Controls: Segment critical workloads. For instance, if an attacker does execute code on a less critical instance, network ACLs and security groups should limit that instance’s ability to reach other sensitive systems (minimizing what execution can achieve). Also, for highly sensitive instances, consider disabling instance metadata or restricting it (v2), to prevent code from easily grabbing new credentials for lateral movement.
Use AWS Managed Services: Whenever possible, use AWS managed services for compute (like AWS Fargate for containers, or Lambda) which have a smaller attack surface (no underlying OS for attackers to persist on or exploit). Managed services also integrate with CloudTrail well for auditing. If you don’t need direct shell access to servers, consider using these – it limits what an attacker can execute or at least makes their actions fully API-traceable.
Persistence
Overview:Persistence refers to techniques attackers use to maintain theirfoothold in your AWS environment, even if initial access points are discoveredor credentials are rotated (Persistence,Tactic TA0003 - Enterprise | MITRE ATT&CK®). In AWS, adversaries oftenestablish persistence by creating new credentials or resources under theircontrol. For example, they might add an Access Key to an existing IAMuser, create a new IAM user with admin privileges (a “backdoor” account), orupdate an IAM role’s trust policy to allow them access from an externalaccount. MITRE notes that in cloud environments, attackers may “addadversary-controlled credentials to a cloud account to maintain persistentaccess” (Persistence,Tactic TA0003 - Enterprise | MITRE ATT&CK®). A real-world case: anattacker who briefly compromises an admin user could create a new IAM user or anew access key on that account so they can continue accessing AWS even if theoriginal credentials are locked down. Another example is creating a scheduledLambda function or CloudWatch Event that continuously runs malicious code –even if one instance is cleaned up, the scheduled task could re-deploy it.
AWS Services/Logs to Monitor:
AWS CloudTrail – CloudTrail is crucial for catching persistence mechanisms. Key events to monitor include IAM operations such as CreateUser, CreateAccessKey, AttachUserPolicy/PutUserPolicy, AddUserToGroup, CreateLoginProfile (enabling console access for a user), and UpdateRoleTrustPolicy (which could let the attacker assume a role). For instance, if you see a CreateAccessKey event for a user that was previously dormant, that’s a sign someone might be establishing a new login method. CloudTrail will log these events with the actor identity, so you can see if an unusual user or IP performed them.
Amazon GuardDuty – GuardDuty has a Persistence category of findings. It looks for patterns like new API keys or suspicious IAM changes after a compromise. A notable example: GuardDuty will generate a finding if it detects a new IAM user creation from an IP address that’s on a threat list or if an access key that was created is being used in an anomalous way. According to AWS, GuardDuty’s persistence threat purpose “could include creating a new IAM user after gaining access through a compromised user’s credentials.” (GuardDuty finding format - Amazon GuardDuty). In other words, if an attacker does create a backdoor IAM user, GuardDuty may flag it, especially if followed by malicious activity.
AWS IAM Access Analyzer & CloudTrail – IAM Access Analyzer can help flag overly permissive policies or changes that grant broad access. While it’s more of a preventative tool, it can indirectly highlight persistence methods (e.g., an attacker attaches a policy with *:* permissions to their new user – Access Analyzer would flag this as a finding). These findings can be sent to Security Hub. CloudTrail logs would show the action that created such a policy.
AWS Config – If enabled for IAM resources, AWS Config can track the creation and configuration changes of IAM users, groups, roles, and keys. Config rules (or AWS Security Hub’s CIS AWS Foundations checks) can detect if IAM best practices are violated, such as an access key creation for the root account (which is almost always suspicious). While Config is not real-time like CloudTrail, it provides a historical record and can alert on changes (e.g., via Config Rules for “no new IAM users without MFA”).
Detection Strategies:
CloudTrail IAM Event Monitoring: Set up a CloudWatch Events rule or a Security Hub custom insight to alert on critical IAM changes. Examples: any CreateUser, CreateAccessKey, or AttachPolicy event could warrant review. Legitimate admin activity might trigger these, but they are infrequent. You can refine by user – e.g., if your DevOps admin is creating a user, perhaps expected; but if an application role creates an IAM user, that’s unusual. An AWS CloudTrail Insights feature can even automatically detect unusual API call volume, which could catch a flurry of IAM modifications.
Multiple Access Keys: AWS IAM users are typically limited to two access keys, but normal practice is often one key per user (or none, using roles instead). If you see a user suddenly has a second key created (CreateAccessKey event) out of schedule, it could be an attacker adding a key. For instance, an attacker on a stolen console session might add an API key for persistence. A simple CloudWatch Logs Insights query on CloudTrail could filter CreateAccessKey and list the affected userIdentity.userName and the source IP. Similarly, track CreateLoginProfile – if a previously programmatic-only user (key-based) suddenly gets a login profile (password set), someone might be enabling console access for persistence.
GuardDuty “New Credentials” Findings: GuardDuty has specific findings like IAMUser/CredentialAccess or Persistence:IAMUser/NewCredentials (naming can change with updates) which indicate suspicious creation or use of new credentials. For example, if an IAM user is created and then immediately used from a known malicious IP, GuardDuty will scream. SOC analysts should integrate GuardDuty alerts into their SIEM or Security Hub and treat any persistence-related alerts with high priority.
Unauthorized Changes: Monitor for failed attempts to create persistence as well – multiple AccessDenied events for IAM actions could mean an attacker is trying different ways to persist (for example, they try to create a user and get denied, then try to attach a policy to an existing role, etc.). Those failures will show in CloudTrail (errorCode fields). While one-off AccessDenied is normal (developers hitting a permission boundary), a sequence of different IAM operation failures by the same actor could indicate malicious exploration.
Scheduled Task Persistence: Check for creation of AWS resources that could re-launch attacks automatically. This includes CloudWatch Events (EventBridge) rules, AWS Lambda scheduled triggers, Step Functions, or even autoscaling policies that launch instances. CloudTrail’s PutRule (for EventBridge) or CreateFunction (Lambda) events can reveal if an attacker set up an automated persistence mechanism. For example, an attacker might drop a Lambda that runs every hour, which could re-establish a backdoor. Use CloudTrail to spot new EventBridge rules or unusual Lambda function deployments. GuardDuty may not catch these directly, so manual monitoring or AWS Config rules are useful.
Mitigation and Best Practices:
Strict IAM Controls: Follow least privilege religiously for IAM. Only a very small number of administrator roles should be able to create new IAM users or modify policies. Consider using IAM permission boundaries to prevent even those with some IAM rights from escalating beyond a set limit. For example, a developer might create roles for Lambda, but a boundary prevents them from attaching policies that exceed their own permissions. This can thwart an attacker using a lower-level account to persist with a higher-privilege backdoor.
MFA on Sensitive Operations: While AWS IAM doesn’t natively support MFA enforcement per action, you can use workarounds. Require IAM users to use roles for administrative tasks and enforce MFA on role assumption. That way, even if an attacker steals an admin’s key, they cannot use it to call CreateUser or AttachPolicy unless they also have the MFA token. This indirectly protects persistence-related API calls). Also enable “MFA-delete” on S3 buckets to prevent attackers from removing versioned data (persistence of data vs. anti-impact, but related to maintaining control).
Continuous Monitoring and Auditing: Set up AWS Config rules or Security Hub standards that detect changes like “Ensure no IAM user creation without approval”. While some drift might be legitimate, treating any new IAM principal as an event that requires security review will drastically reduce an attacker’s ability to hide. Regularly audit IAM users, keys, and roles – if one appears that no one on your team recognizes, investigate immediately.
GuardDuty and Logging Always On: Ensure GuardDuty is enabled in all accounts and regions. It’s relatively low-noise for IAM persistence issues and can catch things humans might miss. Similarly, CloudTrail should be enabled in all regions (including optional global service logging) so that even if an attacker tries to create resources in an unmonitored region, you catch it. Store CloudTrail logs in an S3 bucket with access logging and possibly an immutable configuration (to prevent attackers from cleaning up their tracks).
Limit Long-Term Credentials: Where possible, eliminate IAM users in favor of federated access or assume-role workflows. If there are no long-term IAM users to abuse, attackers cannot create persistent IAM users or keys. AWS Organizations can service-control disallow creating IAM users in member accounts if you choose to go completely federated. At the very least, avoid using the root account for anything and never create access keys for root – that is a common attacker goal and should be explicitly monitored (Security Hub has a control for root key presence).
Privilege Escalation
Overview:Privilege Escalation in AWS is when an attacker tries to gainhigher-level permissions or expand their access after initial compromise. Thisoften means going from a limited user or role to one with full adminprivileges. AWS environments have nuanced privilege escalation paths – forinstance, an attacker with some IAM permissions could attach a policy tothemselves to grant admin rights, or use the PassRole mechanism to pivotinto a more privileged role via a service. In cloud contexts, MITRE recognizesthat valid cloud accounts can be abused for Privilege Escalation orDefense Evasion (ValidAccounts: Cloud Accounts, Sub-technique T1078.004). AWS GuardDuty definesthis tactic as detecting behavior “an adversary may use to gain higher-levelpermissions” (GuardDutyfinding format - Amazon GuardDuty). For example, an adversary whocompromises a developer’s IAM user might attempt to escalate by adding thatuser to an Administrator group or by creating a new EC2 instance with an adminrole attached (then stealing the instance’s role credentials). PrivilegeEscalation is a critical phase, as it often precedes the most damaging actions.
AWS Services/Logs to Monitor:
AWS CloudTrail – Monitor all IAM-related API calls and any changes to policies or roles. Key events include AttachUserPolicy / AttachGroupPolicy, PutRolePolicy, AddUserToGroup, UpdateAssumeRolePolicy, PassRole, and CreatePolicy. Also watch for STS AssumeRole events, especially if an entity assumes a role with higher privileges or a cross-account role. CloudTrail will show the source principal and the target role assumed. Any unusual assume-role activity could indicate an attempt to escalate into another role. For instance, if a lambda function role suddenly assumes the Administrator role, something’s off.
AWS IAM Get APIs* – While not changes, if an attacker is plotting escalation, they might use calls like GetUser or GetRole to inspect their own permissions, or ListPolicies to find a policy ARN to attach. CloudTrail logs such read-only calls too. A surge in IAM Describe/List calls by a principal followed by a privilege change could be a telltale sign of escalation attempts (Discovery preceding Privilege Escalation).
Amazon GuardDuty – GuardDuty has specific findings for privilege escalation attempts. For example, it might detect if a user tries to assign themselves administrative privileges (PrivilegeEscalation:IAMUser/AdminAccess type finding) or if a normally low-privilege user suddenly performs high-privilege actions. GuardDuty’s PrivilegeEscalation threat purpose covers patterns like “a principal trying to gain higher-level permissions” (GuardDuty finding format - Amazon GuardDuty). One concrete finding is Policy:IAMUser/RootCredentialUsage – if an IAM user obtains the API keys of the root account (extreme case), or UnauthorizedAccess:IAMUser/PrivilegeEscalation if a user tries to create an EC2 with a more privileged role attached. These are immediate high-severity alerts.
Security Hub Insights – If you use AWS Security Hub, it can help by consolidating findings related to privilege escalation. For example, Security Hub’s AWS Foundational Best Practices checks include ensuring no IAM policies allow wildcard admin access, etc. While preventative in nature, a deviation from these could indicate someone (attacker) created an overly permissive policy. Moreover, any GuardDuty finding about Privilege Escalation will appear in Security Hub, so you can create a custom insight like “All GuardDuty findings where type includes PrivilegeEscalation” to quickly view them.
Detection Strategies:
IAM Policy Changes: Immediately investigate changes that grant broad privileges. For example, if CloudTrail logs show AttachUserPolicy with arn:aws:iam::aws:policy/AdministratorAccess on a user, that’s a blatant privilege escalation (unless done during a legit break-glass event). A CloudWatch Events rule can catch this exact scenario and alert the SOC. Even attaching PowerUserAccess or creating a custom policy with wildcards (e.g., policy document with "Action":"*" and "Resource":"*") should trigger alarms. CloudTrail’s event detail will contain the policy JSON in many cases; one can parse it to detect wildcards (Persistence, Tactic TA0003 - Enterprise | MITRE ATT&CK®). AWS Config also has a managed rule to flag if an IAM policy becomes overly permissive.
Use of PassRole: The iam:PassRole permission allows passing an existing role to a service (like launching an EC2 instance with that role). Attackers often exploit overly broad PassRole permissions to escalate. For instance, if an adversary can pass any role and can launch a Lambda or EC2, they might pass the OrganizationAdmin role to a new instance, thereby effectively escalating. Monitor CloudTrail for PassRole events. Specifically, check if the role being passed is highly privileged (e.g., contains AdministratorAccess). Also, check the context: who is calling PassRole? If it’s not your deployment pipeline or expected service, it could be malicious. In CloudTrail, a RunInstances event with a iamInstanceProfile parameter referencing an admin role is a red flag.
STS AssumeRole Patterns: Review STS AssumeRole usage. If an IAM user that normally never uses STS suddenly assumes a role, find out why. Also, cross-account role assumptions are logged – if an external account ID is assuming a role in your account (or vice versa), verify that’s intended. Attackers who gain some foothold might try to pivot to another AWS account in your org (lateral movement with privilege escalation). GuardDuty’s UnauthorizedAccess:AssumeRole finding triggers when someone tries to assume a role they’re not allowed to, which is an explicit sign of escalation attempt. Even successful AssumeRole by a new actor should be scrutinized (e.g., if DevAccountUser assumes ProdAdminRole – is that normal?).
Creation of Shadow Admins: This is a scenario where an attacker might create a new IAM user and grant it admin rights (which is both persistence and privilege escalation). We covered detection of new IAM users under Persistence. To detect privilege escalation specifically, focus on the granting of privileges aspect: e.g., AttachGroupPolicy adding AdministratorAccess policy to a group. If that group is “Developers” and suddenly it has AdminAccess attached, now all devs are admins – likely an escalation (or grave error) that should be fixed. Use Config rules or CloudTrail alarms to catch admin policy attachments.
Unusual Console/Admin Activities: Sometimes escalation is evident via the AWS Management Console: a telltale sign is if a lower-level user suddenly has access to parts of the AWS console they shouldn’t. While this is hard to monitor via logs in real-time, user behavior analytics or CloudTrail events like ConsoleLogin by a user followed by a flurry of high-privilege API calls (EC2, RDS, IAM changes) can indicate that user just escalated their privileges (either legitimately or not). CloudTrail’s eventName and userIdentity.arn together with sourceIPAddress can show, for example: a user from an IP logs in and then from the same IP a minute later, that user’s ARN is making sensitive API calls. If that user wasn’t supposed to be able to, something changed – perhaps they added themselves to the Admin group via another session.
Mitigation and Best Practices:
Role Separation and Boundary Policies: Use permission guardrails to technically prevent escalation. For example, do not grant the ability to attach any policy. Instead, if a role must attach policies, limit it to attaching only specific ARNs. Use permission boundaries for IAM roles that developers use, ensuring they cannot grant more than, say, write access to specific services. This way, even if a dev role is compromised, it literally cannot escalate beyond the boundary by design.
Secure Administration Model: Limit interactive access to sensitive admin roles. Instead of having many IAM users with admin rights, consider a break-glass role that requires MFA and maybe external approval (if possible). Use AWS SSO or MFA tokens that rotate. The fewer people and processes that can change IAM roles/policies, the lower the chance an attacker can exploit one. Additionally, maintain an “audit” trail: have CloudTrail send IAM change events to an SNS topic or Slack for real-time awareness among the team when something changes at the privilege level.
Review Trust Policies: AWS IAM roles’ trust policies (who can assume them) are a common escalation vector. Regularly review trust policies for any wildcard or overly broad allowances (e.g., Principal: {"AWS": "*"} is dangerous). Use IAM Access Analyzer to find roles that trust external accounts. If an attacker compromises an external account that had been whitelisted, they could escalate into your account – remove any unused trust relationships.
Disable or Delete Unused Credentials: Old IAM users or roles that are no longer needed should be removed. Attackers often target dormant accounts because they may have high privileges that went unnoticed. Also apply the principle of ephemeral access: use AWS SSO or temporary credentials for admins so there are no standing “keys to the kingdom” to escalate with.
Simulated Attacks & Patching: Stay up to date on known AWS privilege escalation methods (like those documented by penetration testers). Simulate them in a controlled manner to ensure your detections and preventive controls work. AWS regularly patches the platform to close escalation paths, so ensure your environment is modern (for example, older AWS services had legacy roles that could be misused – deprecate those).
Education and Process: Make sure any legitimate use of high privilege (e.g., cloud engineers doing something risky) goes through change management. If a dev needs admin for a task, they should request it and it should be time-bound. This way, any out-of-process change is clearly malicious. In summary, lock down IAM tightly and treat it as the keys to the kingdom – because it is.
Defense Evasion
Overview:Defense Evasion encompasses techniques an attacker uses to avoiddetection and bypass security controls. In AWS, defense evasion often meansattempting to disable or tamper with logging, alter configurations, or usecovert channels to hide activity. Examples include turning off CloudTraillogs, deleting S3 log buckets, disabling GuardDuty or other detective services,or using anonymization (like TOR) to hide the source of their actions.According to AWS GuardDuty’s classification, this covers any activity “anadversary may use to avoid detection while infiltrating your environment” (GuardDutyfinding format - Amazon GuardDuty). In practice, once attackers gainaccess, they might stop CloudTrail for a while to perform actionsinvisibly, or remove CloudTrail log files, or route traffic throughbastion hosts to hide their true IP. They could also modify resource policiesto prevent security services from functioning (for instance, altering an S3bucket policy to disable access logging). Another example: an attacker mightuse an anonymous proxy or TOR to connect to AWS – GuardDuty marks suchevents as Stealth (a subcategory of Defense Evasion), meaning theattacker is “actively trying to hide their actions” (GuardDutyfinding format - Amazon GuardDuty).
AWS Services/Logs to Monitor:
AWS CloudTrail – Ironically, CloudTrail itself is both the target for evasion and a key log source to detect evasion attempts. Monitor CloudTrail for any calls to CloudTrail management APIs: StopLogging, DeleteTrail, UpdateTrail (especially if it removes event selectors or stops logging certain services). These events should almost never occur in a well-run environment (especially DeleteTrail). CloudTrail logs them if they happen (Investigating lateral movements with Amazon Detective investigation and Security Lake integration | AWS Security Blog), so a quick detection is possible. Also watch for attempts to disable other security services: calls like DeleteDetector (GuardDuty API) or DisableSecurityHub. If an attacker tries to cover their tracks, these are obvious moves.
Amazon GuardDuty – GuardDuty has Stealth and Defense Evasion finding types. For example, Stealth:IAMUser/CloudTrailLoggingDisabled is a GuardDuty finding specifically if CloudTrail logging is turned off by an IAM user (Amazon Web Services Security Control Mappings to MITRE ATT&CK®). Similarly, if an attacker uses a TOR exit node to make API calls, GuardDuty will generate UnauthorizedAccess:IAMUser/AnonymousIPCaller, flagging that the traffic is coming from an anonymity network. Such findings directly indicate defense evasion: either log tampering or identity obfuscation. GuardDuty’s DefenseEvasion threat purpose in findings aligns with MITRE’s tactic and will call out patterns of avoiding detection (GuardDuty finding format - Amazon GuardDuty).
S3 and CloudWatch Logs – If CloudTrail (or other logs) are delivered to S3, enable S3 Access Logs on those buckets or AWS CloudTrail log file integrity validation. If an attacker tries to delete or alter log files in S3, the access logs (to a separate bucket) or the CloudTrail integrity checks can reveal that. CloudWatch Logs doesn’t easily allow deletion of specific entries without access to the log group; monitor CloudWatch Logs for any DeleteLogGroup or DeleteMetricFilter API calls via CloudTrail.
AWS Config & CloudFormation – AWS Config can detect if certain security configurations change. For example, Config rules can alert if CloudTrail or GuardDuty is not enabled. If an attacker disables GuardDuty, you’ll miss GuardDuty’s own finding, but a Config rule or Security Hub guardrail control can catch that GuardDuty is off. CloudFormation comes into play if an attacker tries to quickly tear down multiple resources or launch an alternative infrastructure to avoid detection; however, that’s less about evasion and more about efficiency. Still, unusual use of CloudFormation scripts could warrant a look.
Detection Strategies:
CloudTrail Self-Protection: Treat any CloudTrail management event as an immediate incident. If StopLogging occurs, assume an attack in progress: the SOC should be alerted within seconds. Implement a CloudWatch Events rule on StopLogging and DeleteTrail to send an alert (or even run a Lambda to immediately re-enable logging if possible). The same goes for GuardDuty: a call to DeleteDetector in CloudTrail should trigger an alert that your threat detection might be being shut off. It’s essentially the equivalent of an attacker killing an antivirus process on a server.
Missing Logs: If you have centralized logging (e.g., all CloudTrail logs to an S3 bucket or Security Lake), set up a mechanism to detect if logs stop coming in from any region or account. For instance, if CloudTrail logs from a particular region suddenly cease, that could indicate StopLogging was invoked. Some organizations use a heartbeat function or CloudWatch metric for the expected number of CloudTrail events per hour; a sudden drop to zero triggers an alarm. This helps catch evasion even if the attacker doesn’t call an API (e.g., if they somehow caused an error in logging or are operating in an unmonitored region).
GuardDuty Stealth Alerts: Leverage GuardDuty’s built-in detections for evasion. A Stealth finding like “an adversary is using an anonymizing proxy” (GuardDuty finding format - Amazon GuardDuty) indicates someone is trying to hide their source. While not all uses of VPNs are malicious, GuardDuty is pretty good at identifying known bad anonymity infrastructure. Investigate these events – if they coincide with sensitive API calls in CloudTrail (you can correlate by timestamp and source IP), you might catch the attacker’s actions. Also, a “DNS data exfiltration” finding (Backdoor:EC2/DNSDataExfiltration) could be considered defense evasion, as it’s using DNS to sneak data out. It's a crossover with Exfiltration, but also a method to evade traditional network monitoring.
Honey Tokens or Canary: Consider deploying a “canary” in your environment: for example, a fake trail named "DefaultTrail" that isn’t actually critical, and alarm on any attempts to modify it. Similarly, a dummy IAM user or key that, if used, indicates compromise. This isn’t AWS-native functionality but a security technique. If an attacker is poking around, they might try to disable what looks like CloudTrail – if that triggers an alarm (because it was a trap), you’ve detected them in the act of evasion.
Check Unusual Network Paths: Attackers may route traffic through less monitored channels. For instance, instead of accessing an EC2 instance via SSH (which might be monitored), they might tunnel commands through an allowed port or an AWS service. If you notice odd patterns in VPC Flow Logs, such as an instance that normally only connects to AWS services now making outbound connections on high-numbered ports to unfamiliar IPs, this could be an attempt to hide communication (over non-standard ports or encrypted channels). While this borders on Command & Control detection, it’s part of evasion to use ports/protocols that blend in with normal traffic.
Anomalous Resource Changes: An attacker might modify a resource to evade detection. For example, changing a Security Group to open a port to an IP that is a jump box under their control (to bypass stricter networking rules elsewhere). Watch for changes like Security Group rules being altered (CloudTrail logs AuthorizeSecurityGroupIngress/Egress). If an normally-closed environment suddenly has 0.0.0.0/0 allowed on a management port, that could be the attacker circumventing network controls (both evasion and lateral movement prep). CloudTrail and VPC logs together can confirm this – you’d see the SG change then new traffic flows.
Mitigation and Best Practices:
Lock Down Logging and Monitoring: Use AWS Organizations or SCPs to prevent tampering with CloudTrail and GuardDuty. For example, you can apply an SCP that explicitly denies cloudtrail:StopLogging or cloudtrail:DeleteTrail for all principals except maybe a break-glass role. Similar SCPs can protect GuardDuty (deny guardduty:DeleteDetector). This ensures that even if an attacker gets high privileges, they cannot easily blind you.
Multi-Account Log Archival: Aggregate logs to a dedicated security account (e.g., using AWS Security Lake or central S3). Configure the CloudTrail in each account to send to a central S3 bucket in a separate account that the compromised account’s users have no access to. This way, even if they delete the local trail or logs, a copy is preserved out-of-reach. Use the CloudTrail log file validation feature to detect any changes to log files.
Enable Global Services Logging: Don’t forget to have CloudTrail log global service events (like IAM, STS, CloudFront) in each region’s trail. Otherwise, an attacker might switch to a region where logging is off by default or use global services (which if not logged, is an evasion). New AWS regions are not automatically covered by older trails – turn on the “apply trail to all regions” option so that even in regions you don’t use, an attacker’s activity is logged.
Network Egress Controls: To combat covert exfiltration or C2 (which are evasion techniques), restrict outbound network access. Utilize AWS Network Firewall or NAT Gateway allow lists so that instances can only talk out to expected endpoints (e.g., patch repositories, known APIs). This makes it much harder for an attacker to use obscure protocols or external hosts for evasion, because the traffic would be blocked or at least logged by the firewall.
Consistent GuardDuty Deployment: Ensure GuardDuty is on in all regions and accounts and ideally use an AWS Organizations integration so it’s harder for anyone to disable in one account without detection. Regularly check that GuardDuty and Security Hub are still enabled (you can script this or use AWS Config managed rules). This provides continuous coverage and makes it more likely you catch their evasion tries (as ironically, an attempt to disable GuardDuty will often be the thing GuardDuty detects!).
Rotation and Cleanup: If an attacker does succeed in evading for a time, you want to limit the damage window. Ensure that sensitive logs (like CloudTrail) are streamed and analyzed in near-real-time so even if an attacker managed to stop logging at 12:00, you have up-to-11:59 events to work with. Also consider fail-safe: if your detection systems notice they are being inhibited (like GuardDuty not sending heartbeats), have an automated response to elevate to human intervention immediately.
Defense in Depth: Finally, remember that AWS security is one layer – if an attacker is in a position to try defense evasion, ideally your other controls (host IDS, application monitoring) might pick up something is wrong. Use redundant monitoring: for instance, VPC Flow Logs can sometimes reveal actions even if CloudTrail was off, or CloudWatch can have metrics indicating unusual activity. A robust incident response plan that includes alternate ways to assess what's happening (if primary logs are compromised) is crucial.
Credential Access
Overview: The Credential Access tactic involves an adversary trying tosteal account credentials, tokens, or keys. In AWS, this can mean grabbing IAMuser access keys, extracting secrets (passwords, API keys) from AWS SecretsManager or Parameter Store, or dumping credentials from EC2 instance metadata.Since AWS predominantly uses access keys and temporary tokens for auth,attackers focus on obtaining those. MITRE highlights Cloud CredentialDumping as a technique (e.g., stealing cloud service keys. For example, anattacker who gains OS-level access to an EC2 might query the InstanceMetadata Service for temporary credentials attached to that instance’s IAMrole. Or they might list and retrieve secrets from Secrets Manager if theircompromised account has that permission. Even without initial admin access,they might attempt to phish an AWS console login or exploit an identityprovider integration to get valid tokens. In essence, credential access in AWSis about harvesting any form of authentication that would let the attackerre-enter or move laterally – this includes user passwords, MFA tokens, accesskeys, IAM role temp credentials, and API keys for services integrated with AWS.
AWS Services/Logs to Monitor:
AWS CloudTrail – CloudTrail is a primary source for detecting credential harvesting attempts. It will log unusual API calls like: GetSecretValue (retrieving a secret from Secrets Manager), GetParameter (especially if WithDecryption=true for SecureStrings in SSM Parameter Store), Decrypt on KMS (someone trying to decrypt data blobs, possibly to unlock stored credentials), and GetSessionToken or AssumeRole (could be used by an attacker to mint new temporary credentials if they have the right access). Also monitor DescribeInstances or DescribeSnapshots followed by GetPasswordData (used to get the Windows admin password for EC2 – an attacker might use it to retrieve credentials for Windows servers). CloudTrail logs all these accesses. Notably, if an attacker is trying many IAM actions to enumerate or retrieve credentials, you might see a high volume of AccessDenied for calls like ListAccessKeys on accounts they don’t own, etc.
Amazon GuardDuty – GuardDuty’s CredentialAccess findings detect patterns consistent with credential theft (GuardDuty finding format - Amazon GuardDuty). For example, “InstanceCredentialExfiltration” detects if credentials from an EC2 instance are used from an external IP (meaning the credentials likely got stolen off the instance). There’s also a finding for unusual IAM policy interrogation which might be an attacker looking for credentials or secrets. GuardDuty watches for things like an IAM role making API calls outside of AWS IP address ranges (signaling the instance credentials were taken out). If malware on an instance tries to scrape creds and send them out via DNS or other channels, GuardDuty might flag the DNS behavior as well.
AWS CloudWatch Logs (OS Logs) – If you forward system logs from EC2 (via the CloudWatch agent or SSM) or container logs, you might catch local clues of credential access attempts. For example, entries in /var/log secure about AWS keys, or application logs showing errors accessing metadata service (if attacker is poking it). These are harder to use at scale, but in targeted cases can help.
VPC Flow Logs – Unusual internal calls can be detected here. The Instance Metadata Service is accessed at 169.254.169.254 (http) from within EC2. Normally only the instance itself should call it. If you have flow logs enabled, an attacker inside the instance querying metadata is normal (the OS does it). But if they somehow try to pivot and query metadata of another instance via SSRF, you might see egress from one instance to another’s IP on 169.254/16 – though AWS blocks metadata requests across VPC by default. Flow logs also can detect large exfiltration of data that might include credentials (overlaps with Exfiltration tactic).
Detection Strategies:
Secrets Manager and Parameter Store Access: These services contain sensitive secrets by design, so any access to them should be tightly monitored. If your environment rarely reads certain secrets (especially by IAM users), you can set alerts on GetSecretValue. AWS CloudTrail offers the ReadOnly flag in events; filter where eventSource = secretsmanager.amazonaws.com and eventName = GetSecretValue and examine who is calling it and from where. Similarly, for SSM Parameter Store, look at GetParameter (with requestParameters.name of sensitive parameters). Consider implementing AWS CloudWatch Events rules to specifically catch these calls and send notifications. An example: alert if anyone calls GetSecretValue on a secret that contains the word “prod” or “password” in its name, unless it’s a known service role.
Instance Metadata & Role Credential Exfiltration: On an EC2 instance, if an attacker has OS access, they can get the IAM role’s temporary credentials via the metadata service. While this action (HTTP GET to 169.254.169.254) is not directly visible in CloudTrail, the use of those credentials externally is. GuardDuty’s InstanceCredentialExfiltration is exactly for that scenario: it knows the pattern of an EC2 role’s keys and if they appear from an IP outside AWS, it alerts. So a GuardDuty finding in this realm is a strong indicator of credential compromise. Also, if you see an STS GetCallerIdentity call in CloudTrail from an external IP that corresponds to an IAM role’s credentials (which normally only operate internally), that’s a clue (attackers often invoke GetCallerIdentity to test if the stolen creds work and see who they are). You can attempt to detect this by correlating CloudTrail events: a AssumeRole was used to issue temp creds to EC2, and later that same role ARN is used from a different IP outside. Such correlation is complex manually, but tools like Detective or custom SIEM rules can do it.
Brute Forcing Credentials: Although AWS keys are not easily brute-forced (they’re high entropy), an attacker might try password brute force on the AWS Console. This would show up as many failed ConsoleLogin attempts (with different passwords) for a user. CloudTrail logs an event for each failed login (with errorMessage: "Failed authentication"). Multiple failed console logins for a single user could indicate password guessing – this is something to alert on (as part of Initial Access as well). Additionally, if someone tries to use the AWS CLI with a deactivated or incorrect access key, those don’t show in CloudTrail of the target account (because it fails to authenticate). However, an attacker might enumerate account IDs and try guessing keys – those won’t be seen until successful. So not much to detect on AWS side except maybe your web application firewall logs if they try web brute force.
Credential Exposure via Logs: Sometimes credentials get accidentally logged or stored in places. If an attacker has read access to CloudWatch Logs, S3, or DynamoDB, they might search for strings that look like access keys (Access Key IDs have a specific pattern (AKIA...), etc.). Monitoring for unusual read access to large volumes of data (overlaps Discovery) might catch an attacker scanning for creds in storage. Macie can detect if secrets (like AWS keys or passwords) are present in S3 buckets. If Macie flags "Access key detected in S3," that’s both a vulnerability and possibly an attacker plant or find. Treat those seriously.
Excessive API Key Creation or use of Unused Keys: If an attacker can’t steal an existing key, they might create new ones (overlap with Persistence). We covered CreateAccessKey earlier. But also monitor the usage of keys: AWS CloudTrail’s userIdentity.accessKeyId field can help identify which key is being used in each API call. If you notice an access key that wasn’t used for months suddenly making lots of calls, that could be a stolen key being leveraged. An analytics approach in a SIEM might baseline key usage frequency and spike on anomalies. GuardDuty may catch unusual usage as AnomalousBehavior or CredentialAccess depending on pattern.
Mitigation and Best Practices:
Secure Secret Storage: Use AWS Secrets Manager or SSM Parameter Store for managing secrets, and lock down who (what roles) can retrieve those secrets. Enable rotation for sensitive secrets so that even if one is stolen, it’s valid only for a short time. For IAM users, enforce password policies (complexity, rotation) and disable console access for accounts that don't need it. Consider requiring hardware MFA for particularly sensitive logins (like using a U2F security key for the root account, which AWS supports).
Reduce Human Access to Sensitive Data: Humans often don’t need direct access to production credentials – applications do. Implement patterns like AWS Systems Manager Session Manager for shell access (so you don’t distribute SSH keys widely), and use Federation for console access (so there are no static passwords to steal for IAM users). The less often secrets and keys are used or exposed, the lower the chance an attacker can grab them.
Instance Metadata v2: Ensure EC2 uses Instance Metadata Service v2 (IMDSv2) which is enabled by default on newer instances. IMDSv2 protects against SSRF attacks stealing role credentials by requiring a session token. It’s not foolproof (if attacker fully compromises instance, they can still get creds), but it helps against certain web app attacks that could otherwise retrieve credentials.
Monitor and Limit API Credentials: Use Amazon IAM Access Analyzer to find any credentials (keys) that have leaked publicly (it can detect if an access key shows up in public GitHub commits, for example). Immediately disable any compromised credentials. Implement a tight process for issuing and rolling keys – for example, use CI/CD to provide temporary access keys for builds rather than long-lived keys in config files. If possible, no IAM user should have an access key unless absolutely necessary; prefer roles and federation. This way, stealing long-term credentials is much harder for an attacker.
Zero Trust & Assume Breach: Even with all precautions, assume an attacker could get some credentials. Employ compensating controls like resource-level permissions (an access key for an app that only allows reading a specific S3 bucket is of limited value to an attacker – they can’t escalate with it easily). Encrypt sensitive data with KMS and ensure the principals that can decrypt are limited (so even if they steal the data, they need the KMS decrypt permission which they might not have). This aligns with the idea: even if an attacker steals credentials for one component, they shouldn’t automatically get access to everything.
Continuous Auditing and Key Rotation: Regularly rotate IAM access keys (and definitely if you suspect compromise). Use AWS Credential Reports to identify old unused keys and remove them. Turn on AWS CloudTrail tracking of management events and data events where possible (S3 data events for buckets with keys or secrets). The faster you detect a credentials issue, the quicker you can mitigate by disabling those creds. Security Hub has a finding if access keys are over 90 days old (per CIS benchmark), which is a baseline hygiene measure.
Incident Response Prep: Plan for a scenario of credential compromise. Have automation ready (via Lambda or CLI scripts) to disable credentials or lockdown roles at a moment’s notice. AWS IAM allows you to deactivate access keys and require MFA – knowing which commands to run (and having them scripted) can save precious minutes if you see that keys are in the wrong hands.
Discovery
Overview: In the Discovery phase, an attacker explores the compromised AWSenvironment to understand what resources, accounts, and configurations exist.The goal is to gather information that can inform next steps (like privilegeescalation, lateral movement, or locating target data). In AWS, Discoveryoften involves enumerating cloud resources and services via AWS APIs (CloudService Discovery, Technique T1526 - Enterprise | MITRE ATT&CK®). Forexample, an adversary might list all S3 buckets, describe EC2 instances and EBSvolumes, enumerate IAM users and roles, or query AWS Systems Manager ParameterStore for any parameters. They may also try to discover security measures –such as checking if GuardDuty is enabled or if CloudTrail trails exist (yes,attackers might even look for GuardDuty or CloudTrail, as noted in MITRE’sCloud Service Discovery) (CloudService Discovery, Technique T1526 - Enterprise | MITRE ATT&CK®).Essentially, the attacker is mapping out your AWS infrastructure andconfigurations: this could include VPCs, subnets, security groups (to find openports or reachable subnets), Lambda functions, RDS databases, etc. On thenetworking side, Discovery can also mean port scanning within the cloudenvironment (e.g., an EC2 instance scanning others in the VPC). All these helpthe attacker identify where valuable data or higher privileges might be and howto get to them.
AWS Services/Logs to Monitor:
AWS CloudTrail – CloudTrail logs are a treasure trove for catching discovery activity, since most of it involves API calls. Watch for a high volume of Describe, List, and Get API calls across many services. For instance, DescribeInstances, DescribeSnapshots, ListBuckets, ListSecrets, ListUsers, DescribeDBInstances, etc. A single principal invoking an unusual breadth of read-only APIs (especially if they typically don’t) is a sign of scanning. CloudTrail will record each call along with source IP and user agent – if the calls come from a programmatic user agent (like Boto3/Python or AWS CLI) in a short span, it could be an attacker’s script doing reconnaissance.
Amazon GuardDuty – GuardDuty detects certain discovery techniques. Specifically, it has Reconnaissance findings: e.g., Recon:EC2/Portscan if an EC2 instance in your account is scanning ports on other hosts (GuardDuty finding format - Amazon GuardDuty), or Recon:IAMUser/MaliciousIPCaller if an IP known for past recon activity calls AWS APIs in your account. GuardDuty’s recon findings highlight enumeration of resources or probing of services. As per GuardDuty, “reconnaissance of your environment to determine how they can broaden their access… including probing ports, making API calls, listing users, and listing database tables” (GuardDuty finding format - Amazon GuardDuty). This aligns exactly with Discovery.
VPC Flow Logs – For network-level discovery, like port scanning or host discovery in the cloud network, VPC Flow Logs are crucial. If an instance is performing internal recon, you might see it attempting connections to many IPs or ports within the VPC. Flow Logs will show a lot of “REJECT” traffic from one source to multiple destinations if security groups or NACLs block the scan, or “ACCEPT” to numerous destinations if not blocked. This kind of pattern (many dest ports, short-lived connections) is indicative of scanning. Even external recon (someone scanning your public IPs) can be caught: if Flow Logs show an external IP hitting many of your IPs/ports, that’s an outside recon. (GuardDuty will catch external scans too, summarizing as finding).
AWS Config Resource Inventory – While not a real-time log, AWS Config keeps an inventory of resources. An attacker with read access might use Config’s inventory or advanced queries to list all resources. If you have AWS Config, you could use its data yourself to detect if any new resources were accessed or if anything was enumerated oddly. However, an attacker using Config APIs (e.g., ListDiscoveredResources) would also show up in CloudTrail, so CloudTrail remains the primary detection source.
CloudWatch Metrics/Alarms – If you suspect internal port scanning, you might create CloudWatch metrics on flow logs (via Logs Insights metric filters) to detect a high number of distinct port connections. Similarly, a metric filter on CloudTrail can count Describe API calls per user. CloudWatch Alarms could then alert on thresholds (e.g., more than 100 describe/list API calls in 5 minutes by one entity). This is a heuristic that indicates possible automated discovery tool usage.
Detection Strategies:
CloudTrail Burst of "Describe" Calls: Look for patterns where a principal is performing a breadth-first search of your environment. For example, an IAM user that normally just interacts with EC2 launching now suddenly calls DescribeInstances, DescribeVpcs, DescribeSubnets, DescribeSecurityGroups back-to-back. You can write a CloudWatch Logs Insights query to count the number of unique API operations by each IAM principal in a given timeframe. A spike in unique API calls (especially read-only ones) is a strong indicator of recon. For instance, if you see an API call count like 50+ different Describe/List operations in an hour by one user, that is very unusual for normal admin work (which tends to focus on a few services at a time).
GuardDuty Recon Alerts: Pay close attention to GuardDuty findings under the Reconnaissance category. Recon:EC2/Portscan means an EC2 instance is likely compromised and scanning others – you should investigate that instance immediately (check its CloudTrail actions, isolate it if needed). Recon:EC2/PortSweep indicates scanning multiple hosts for a single port, etc. Recon:IAMUser/ResourceInventory (if it exists) would mean large-scale listing of resources. Each of these is essentially an alarm bell for discovery activities. They often precede data access or escalation, so catching recon gives you a chance to stop the attack in its planning stage.
Failed Resource Access: Discovery can also generate Access Denied logs if the attacker’s account doesn’t have permissions. For example, an attacker might try DescribeSnapshots but their role isn’t allowed – CloudTrail logs a DescribeSnapshots event with an error. If you see a wave of AccessDenied for different APIs (IAM, EC2, S3, etc.) all from the same principal, that’s likely an attacker figuring out what they can’t see (and by elimination, what they can). A threat hunting query could be: show any principal who has more than X AccessDenied events for different services in the last hour. This could pinpoint a noisy attacker who is blindly trying to list things.
Unusual API User Agent: Many AWS SDKs identify themselves in the userAgent field of CloudTrail (e.g., aws-cli/2.0, Boto3, etc.). If an attacker uses a custom tool or older toolkit, the user agent might stick out (like Botocore/1.12 from a Python script). Tracking userAgent isn’t foolproof (they can set it), but if you normally see only a few types of user agents and suddenly there’s an unusual one performing lots of read calls, consider that suspicious.
Internal DNS Queries: Sometimes discovery involves DNS queries for internal service endpoints or instance names. If Route53 Resolver query logs are enabled, an attacker doing internal recon might try to resolve, say, internal-service.example.local or randomly named endpoints to see what exists. Unusual DNS queries could tip you off. GuardDuty has findings for DNS like “Spike in DNS requests from an instance” which might indicate automated recon or data exfil via DNS. Keep an eye on those as well.
Mitigation and Best Practices:
Principle of Least Privilege (again): Many discovery actions are only possible if the principal has those permissions. For example, if no application roles have iam:ListUsers or s3:ListAllMyBuckets, an attacker compromising one can’t directly list all users or buckets. They might still enumerate by trial and error (checking for access denied vs. granted on certain actions), but tightly scoped IAM policies limit what can be discovered. Always give roles the minimum visibility necessary. If a role doesn’t need to see all S3 buckets, don’t allow s3:ListAllMyBuckets. This way, even if compromised, it can’t reveal the scope of your environment easily.
Network Segmentation: For network discovery, segment your VPCs and restrict Security Groups to limit which instances can talk to each other. If an attacker does compromise one machine, they should not be able to scan the entire IP space of your AWS environment. Use VPC peering or PrivateLink carefully; don’t flat-network everything. The concept of micro-segmentation (each tier or service only communicates with what it must) means port scans will be mostly fruitless or very limited in scope. And any attempt to scan across segments might hit a firewall or NACL which can be logged or alerted on.
Service Quotas and API Throttling: AWS has built-in API rate limits; however, they are usually high for read-only calls. Still, you might implement your own form of throttling by using AWS CloudTrail Insights (which automatically detects unusual API call volume). If an attacker’s discovery triggers a surge in API calls, CloudTrail Insights could flag that anomaly. Ensure CloudTrail Insights is enabled and integrate those findings into your alerting pipeline.
Detection as Deterrent: Realize that thorough discovery by an attacker makes noise – use that to your advantage. If you detect discovery, you can respond before they escalate. So treat discovery alerts (like GuardDuty recon findings or unusual CloudTrail patterns) as urgent. Even if it's a false positive (maybe a new sysadmin running aws inventory script), it’s better to verify. This mindset ensures that if an attacker is mapping your environment, you’re already on to them.
Limit Metadata Exposure: Consider if there’s any metadata or naming in your environment that gives away info. For example, naming conventions that reveal environment or importance (like an EC2 named “Prod-CreditCardDB”). An attacker doing DescribeInstances will immediately spot that. While hard to avoid completely, be mindful of overly descriptive names. Also, AWS tags – sometimes people put sensitive info in tags (like keys or passwords, which is a bad practice). Make sure secrets are not hidden in easily discoverable places.
Continuous Training: Keep your incident response team aware of cloud-specific recon techniques. Run drills where someone performs widespread discovery (with permission) to test if your alerts fire. Use tools like AWS Pacu (an open-source AWS exploitation framework) in a controlled way; it has modules for enumeration. See if your team catches them. This helps fine-tune your detection rules for Discovery without waiting for a real attacker.
Security By Obscurity? While not a primary defense, not advertising certain things can help. For instance, don’t leave unnecessary data accessible that lists all your resources (like an open Confluence page “AWS Inventory”). If an attacker stumbles on internal documentation or config, that accelerates their recon. Lock down documentation and use unique, non-obvious naming where possible. This is more of an opsec measure than a control.
Lateral Movement
Overview:Lateral Movement in AWS involves an attacker moving from theinitially compromised resource to another resource or account in order toexpand control and find valuable assets. In a cloud context, lateral movementcan mean pivoting between AWS accounts (if trust relationships allow) ormoving within an account from one compromised instance to another. Unlikeon-prem where lateral movement is often via internal network exploits, in AWSit frequently uses valid mechanisms like STS AssumeRole to jump intoanother role, or AWS Systems Manager Session Manager to gain shell access oninstances. According to AWS, adversaries with stolen credentials could “useAPIs to interact with infrastructure and even evade defenses to gain directaccess to EC2 instances” (Investigatinglateral movements with Amazon Detective investigation and Security Lakeintegration | AWS Security Blog). For example, an attacker who compromiseda developer account might assume an IAM role in the production account ifallowed (cross-account movement). Or if they compromised one EC2 instance, theymight retrieve its IAM role credentials and then call the EC2 API to startsessions on other instances (via SSM) – effectively moving laterally into thoseinstances. Another lateral movement scenario: using AWS Glue or Data Pipelineto extract data from one resource to another accessible location. The key is theattacker is extending their foothold beyond the initial spot, using whateverpaths the cloud configuration allows.
AWS Services/Logs to Monitor:
AWS CloudTrail – CloudTrail is vital for tracking lateral movement actions such as STS AssumeRole (especially cross-account), AWS SSM StartSession or SendCommand (one instance controlling another), AWS EC2 Instance Connect (SendSSHPublicKey to access an instance via SSH without a key pair), and possibly AWS Organizations API calls (like inviting a new account or switching roles via AWS SSO). Each of these leaves a trace. For instance, an STS AssumeRole event will show the source principal (who assumed) and the target role ARN. If you see an entity from Account A assuming a role in Account B, that’s cross-account movement. If you see an IAM user assume a role within the same account that they normally wouldn’t use, that’s also movement. CloudTrail will also log if someone uses AWS Connect or TransferFamily, but those are less common for lateral movement.
Amazon GuardDuty – GuardDuty can pick up certain lateral movement behaviors. It might classify some AssumeRole misuse under UnauthorizedAccess or PrivilegeEscalation findings. For example, UnauthorizedAccess:IAMUser/ConsoleLogin (not exactly lateral, more initial, skip). But it does highlight scenario: in a recent AWS blog, Detective (related to GuardDuty) identified API calls like ec2-instanceconnect:SendSSHPublicKey as part of lateral movement attempts (Investigating lateral movements with Amazon Detective investigation and Security Lake integration | AWS Security Blog). GuardDuty might not explicitly say "LateralMovement" in findings, but it captures the techniques (like internal port scanning, unusual instance behavior targeting another).
Amazon VPC Flow Logs – If an attacker moves laterally by using one compromised instance to connect to another via SSH/RDP or other service ports, VPC Flow Logs will show network traffic between instances. For example, if instance i-123 connects on port 22 to instance i-456, that is recorded (provided Flow Logs are on for that traffic). If such east-west traffic is not typical (many architectures disallow direct instance-to-instance admin access in favor of SSM), seeing it could indicate lateral movement. Flow logs combined with instance IDs can help confirm that one compromised host is probing or communicating with others.
AWS Systems Manager Session Manager Logs – If SSM Session Manager is used (which is great for secure access normally), each session start is logged in CloudTrail (StartSession) and you can also have Session Manager output logs to an S3 or CloudWatch Logs. An attacker leveraging Session Manager to move around will trigger those logs. Monitoring StartSession events in CloudTrail can reveal if, say, an IAM role that shouldn’t normally start sessions is doing so.
Detection Strategies:
Cross-Account Role Assumption: Identify and alert on unusual cross-account STS AssumeRole usage. Ideally, you know the legitimate cross-account access patterns (like CI/CD from account A assumes role in account B). Any deviations – like an unknown external Account X assuming a role in your account – should be treated as an incident. CloudTrail provides the awsAccountId of the source in the assume role event (in userIdentity.accountId for the principal assuming, and the ARN of target role). Setting up AWS Organizations AWS CloudTrail to log events from all member accounts to one place can help spot cross-account moves. If you see your account’s role assumed by another account not in your org (and you didn’t set that up intentionally), that’s likely malicious. Similarly, if within the org, a low-priv account’s user assumes a role in the admin account, flag it.
EC2 Instance-to-Instance Action: Monitor CloudTrail for usage of EC2 Instance Connect (SendSSHPublicKey). This API lets a user push an SSH key to a running instance’s authorized keys (for 60 seconds) and then they can SSH in without prior key setup. If an attacker has EC2:SendSSHPublicKey permission and knows target instance IDs, they might do this for lateral movement (especially if they compromised one account that has network access to another’s instances). CloudTrail will log SendSSHPublicKey with details like instance ID and target OS user. This is relatively rare in normal use (Session Manager is more common for AWS CLI users), so any such event could be malicious. In fact, as referenced in an AWS blog, detecting a successful SendSSHPublicKey to an unexpected instance was a key indicator of compromise (Investigating lateral movements with Amazon Detective investigation and Security Lake integration | AWS Security Blog).
Unusual SSM Usage: If your environment normally uses Session Manager only from specific jump-off points, then a random role invoking SSM StartSession to an instance is suspicious. For detection, you might correlate that with interactive user IP – e.g., an IP that had AWS Management Console activity, then that same IP shows up in session logs or instance logs via SSM. Detective or manual analysis can tie GuardDuty “new geolocation API calls” with subsequent SSM usage to see lateral move. But simpler: set alerts on SSM SendCommand or StartSession where the caller is not an expected admin role. Also, note the targets: if someone starts a session on an instance that is a high-value asset (like a database server) and that someone is not on the list of admins, you likely have a lateral movement attempt.
Pivot Through Services: Attackers may also move laterally through less obvious means, like sharing an EBS snapshot to another account (then mounting it to read data), or creating a VPC peering to siphon data. Many of these actions will show up in CloudTrail (e.g., ModifySnapshotAttribute making it public or shared, CreateVpcPeeringConnection). If you see resources being shared outside normal patterns, that might be an indicator of lateral movement/exfiltration combined. Keep an eye on snapshot sharing events, S3 object sharing (if a bucket policy suddenly allows another account access). These might indicate the attacker preparing data for exfil or pivoting to process data in their own account.
GuardDuty Lateral Behavior: While GuardDuty doesn’t label something "Lateral Movement," it will catch things like internal brute force (e.g., UnauthorizedAccess:EC2/SSHBruteForce if one of your instances is trying to brute force another internally). That is lateral movement in progress. If you get such a finding, it means one instance (likely compromised) is actively trying to spread to others. Immediate response is needed: isolate that source instance. Also check if it succeeded: maybe after brute forcing, the attacker gained credentials for the target – you might then see that target start doing anomalous things (chain of compromise). So treat GuardDuty internal threat findings as lateral movement indicators.
Mitigation and Best Practices:
Isolate Accounts and Limit Trust: Use AWS Organizations to isolate workloads by account and use strict cross-account role trust policies. If possible, do not use broad trust (“*”) in any IAM role trust policy – specify exactly which account and which principals can assume a role. For highly sensitive accounts, consider removing trust to other accounts entirely. This way, even if an attacker compromises one account, they can’t just assume roles in another because the trust isn’t there. Also routinely audit any cross-account access setup (Access Analyzer can help find roles that any external account can assume). Remove or tighten those trusts if they’re not absolutely required.
Network Segmentation and Private Networking: Ensure that not all instances can reach each other. Use security groups that narrowly allow access. For example, your web servers probably never need to SSH into each other – so don’t allow that. If one server is compromised, it should not have network pathways to others except those essential (like to the database on the DB port, etc., and even that can be restricted). Employing zero trust principles internally (authenticate and authorize every connection) will limit lateral movement options. For instance, require SSM for all admin access and disable SSH entirely – then an attacker can’t SSH even if they open a port, because no key.
Least Privilege on AssumeRole & SSM: Do not give IAM users broad sts:AssumeRole unless needed, and when needed, limit which roles they can assume (using conditions on sts:ResourceTag or specific ARNs). Likewise, control who has the ability to SSM into instances. Perhaps only a break-glass admin role can StartSession on production instances. If an attacker never obtains credentials that have those permissions, they can’t easily move to another instance via SSM or role assumption.
Multi-Factor on Sensitive Lateral Actions: AWS now allows requiring MFA on role assumption (condition in trust policy aws:MultiFactorAuthPresent or via Identity Center session if using SSO). Use this for admin roles. This means even if attacker steals admin’s credentials, they can’t assume the “super-admin” role without MFA. Similarly, consider requiring MFA for IAM users to use certain APIs like EC2 Instance Connect or PassRole, using IAM policies with conditions. These measures can disrupt an attacker’s ability to smoothly move laterally using stolen credentials alone.
Logging and Session Recording: Use Session Manager with session logging. This way, if someone uses SSM to move around, you have a transcript of what they did on the target instance. It might not prevent it, but it aids in incident response and may act as a deterrent if an insider threat knows their sessions are recorded. For SSH, consider solutions like AWS Systems Manager Session Manager to avoid SSH entirely. If you must have bastions, ensure their logs are aggregated and monitor who connects where.
Incident Response Drills: Simulate a scenario where an attacker has one set of credentials in your dev account – walk through what they could do to reach prod. Then ensure you have detective or preventive controls at each step. For example, if dev account has a role that trusts prod, that’s a risk – maybe require approval (via an IAM ExternalId or manual step) for that assumption. Practicing these scenarios helps plug holes that facilitate lateral moves.
Rapid Isolation: If lateral movement is suspected, have playbooks ready to isolate affected resources. AWS has tools like Security Hub’s automated response or Systems Manager to isolate an instance (e.g., by changing its security group to one with no outbound/inbound access, or snapshotting and shutting it down). The quicker you isolate, the harder it is for the attacker to keep moving. Also, if cross-account keys are compromised, be ready to invalidate those (e.g., Delete or rotate IAM roles’ credentials if a role was assumed and creds possibly stolen from that session).
Collection
Overview: In the Collection phase, the attacker gathers the data ofinterest from the environment in preparation for exfiltration. Afterdiscovering where sensitive information resides, they will collect andconcentrate that data. In AWS, this could involve copying data from varioussources into a single staging area. Examples: creating snapshots of EBSvolumes or RDS databases that contain data (Anoverview of CloudTrail events that are interesting from an Incident Responseperspective · GitHub), downloading large numbers of S3 objects, oraggregating logs and files from compromised EC2 instances. MITRE ATT&CK hasa technique “Data from Cloud Storage Object” (T1530) which describesattackers accessing data from services like S3. In practice, an attacker mightuse AWS APIs to systematically retrieve sensitive data: for instance, using theS3 CLI to sync an entire bucket(collection of files), or using ExportSnapshot to export a RDS snapshot to S3, or reading all secrets in SecretsManager. The key difference between Discovery and Collection is that now actualdata content is being gathered, not just metadata. Often, this stage produces largedata access volumes or unusual data aggregation in one place.
AWS Services/Logs to Monitor:
AWS CloudTrail (Data Events) – By default, CloudTrail logs management operations. For Collection, it's critical to also have Data Events enabled for data stores like S3 and Lambda. S3 Data Events log each object-level API call (GetObject, ListObjects, PutObject, etc.). If an attacker is downloading many objects from a bucket, those will show up as a torrent of GetObject events. Likewise, if they use the CopyObject API to copy data to a bucket they control, that’s logged. CloudTrail management logs will capture things like CreateSnapshot (for EBS or RDS) and ModifySnapshotAttribute (e.g., making a snapshot public or shared). Each of these can indicate data is being packaged for theft. If an attacker uses AWS CLI or SDK to collect data, CloudTrail will show the API calls involved in reading that data.
S3 Access Logs/AWS CloudFront Logs – If CloudTrail data events weren’t enabled, but S3 Server Access Logging is on for a bucket, you still get logs (with less detail) of object accesses. These can be used to detect bulk reads after the fact. Similarly, if an attacker is exfiltrating via a CloudFront distribution (if the architecture allows it), CloudFront logs would show unusual downloads. However, enabling CloudTrail data events for S3 on sensitive buckets is strongly recommended for near-real-time visibility.
Amazon Macie – Macie is an AWS service that can detect and alert on suspicious data access patterns and also helps identify sensitive data. Macie can, for example, generate alerts if it sees a large quantity of sensitive files being accessed or if a bucket with sensitive info suddenly becomes public. Macie might classify a bunch of data as PII and then notice if an IAM user reads a pile of it in a short period. These alerts can indicate Collection. Macie focuses on S3, though.
GuardDuty – GuardDuty has some findings relevant to collection/exfiltration. For instance, if an EC2 instance starts communicating with an IP on an unusual port or sends large data out (in a way consistent with known tools), it might flag “Data Exfiltration over DNS” or “Large Volume Traffic” anomalies. While these often fall under Exfiltration and C2, an ongoing collection process that streams data out slowly might trigger a Behavior anomaly finding (like an EC2 suddenly reading lots of S3 data and sending out via an external connection). Also, UnauthorizedAccess:S3/MaliciousIP – if a known bad IP reads S3 objects (implying the attacker made a bucket public and is pulling data), that is a direct sign of data theft in progress.
CloudWatch Metrics – You can set up CloudWatch metrics for certain usage that might indicate collection. For example, for S3 you can monitor the BucketSizeBytes and NumberOfObjects metrics – if these drop suddenly (lots of deletions which could be part of final stage of collection or impact) or if data egress via CloudFront bytes skyrockets. CloudTrail events can feed metrics too, like a custom metric for “# of GetObject calls” on a bucket. Spikes in those metrics might mean collection.
Detection Strategies:
Bulk Data Read: Identify when a principal is reading unusually large amounts of data. If CloudTrail data events are on, you can query or alert when, say, 1000+ GetObject calls occur within an hour by the same user or access key. Or if ListObjects returns an abnormally high count (though CloudTrail logs the call, not the count of objects returned). A CloudWatch Logs Insights query on S3 data events could do stats count() by userIdentity.arn with a filter on eventName = GetObject, to see who is downloading the most. If an attacker is using stolen keys to vacuum a bucket, they will stand out in such analysis.
Creation of Data Archives: Monitor for events like CreateSnapshot of volumes holding data (EBS volumes attached to databases or critical servers) that are not part of routine backups. If an unusual snapshot is created, especially if then ModifySnapshotAttribute is called to share it or make it public, that’s a huge red flag (An overview of CloudTrail events that are interesting from an Incident Response perspective · GitHub). Similarly, CreateDBSnapshot for RDS or ExportDBSnapshot. Attackers may also use AWS DataSync or AWS Glue to aggregate data – those would show up as DataSync task creation or Glue job runs in CloudTrail. If you see a new DataSync task created linking to an internal datastore and an external location, it could be malicious.
Combining Data: If the attacker collects data from multiple sources, they might store it in a new bucket or EBS volume. Watch for creation of new S3 buckets by unusual actors (CloudTrail CreateBucket) especially followed by lots of PutObject from different sources. Or an EC2 instance suddenly receiving lots of data from various places (flow logs show multiple sources sending data to one instance). This could indicate they are staging data on an instance before exfiltration (e.g., assembling a tarball). Unusual inter-region data transfer could also be a clue (like copying a snapshot to another region).
Macie Alerts: If using Macie, leverage it. Macie might alert “Sensitive data (like credit card numbers) read by a user who typically doesn’t access it”. Those behavioral alerts complement your log-based detection. Macie can also tell you if a bucket that was private goes public or if data matching certain patterns is being accessed. Integrate Macie findings into Security Hub or SIEM so they aren’t missed.
Time of Activity: Large-scale collection might be done during off-hours to avoid notice. If you observe heavy data access by a human principal at 3 AM when normally no one works, that’s suspicious. Your detection can include a time component – e.g., an alert if more than X GB of data is read outside of business hours. AWS CloudTrail events have byte counts for some data events (for S3, the object size is in the logs), which you can aggregate to measure volume.
Exploitation of Misconfigurations: If an attacker finds a misconfigured data store (like an open S3 bucket or an RDS with no password), that data might already be at risk. Ensure you have detections for public S3 buckets with sensitive data (Macie helps, or periodic bucket audits). If a bucket suddenly becomes public (CloudTrail PutBucketAcl or PutBucketPolicy making it public), assume the attacker is preparing to collect or exfil data from it. That should be remediated immediately.
Mitigation and Best Practices:
Data Segmentation and Access Control: Limit which principals can access sensitive data and segment data storage. For example, not all application roles should be able to read all S3 buckets. Use S3 bucket policies to allow only specific IAM roles or AWS accounts to access them. Consider VPC endpoints for S3 with policy restrictions so that even if credentials are compromised, access must originate from your VPC (attackers outside would have a harder time). Use KMS encryption on sensitive data with customer-managed keys and restrict key user permissions; that way even if data is copied, without the KMS decrypt permission the data remains gibberish (this mitigates snapshot theft if the volume was KMS-encrypted and the attacker can't use the KMS key).
Monitor and Throttle Data Access: Implement AWS Budgets or AWS CloudWatch Contributor Insights for anomalous data transfer costs or request counts. For instance, if suddenly a bucket sees millions of requests (and cost spikes), that triggers a budget alert. While after-the-fact, it can prompt immediate investigation. AWS also has service quotas; though they are high, you might request to lower certain quotas in your account if possible – to make massive data export harder (not always practical).
Automate Snapshots and Logging: One counter-intuitive mitigation: if you regularly snapshot and log data access for your own needs, an attacker’s similar actions might blend in. However, by doing it yourself in a controlled, monitored way, you can set traps. For example, maintain canary files that only an attacker would go after (like a fake “passwords.csv” in an obscure S3 bucket) and monitor if it’s ever accessed. This helps detect the collection phase specifically targeting juicy files.
Remove Public Access and Unused Data: Ensure no sensitive data store is publicly accessible. Use the AWS S3 Block Public Access at account and bucket level to prevent accidental exposure. Similarly, turn off any unnecessary data sharing services (like if you’re not using AWS Resource Access Manager, an attacker can’t abuse it to share resources). Clean up old data – if something doesn’t exist, it can’t be stolen. Attackers can only collect what you have; enforce data lifecycle policies to delete data that’s no longer needed, limiting what’s available.
DLP Solutions: Though AWS-native DLP is limited to Macie for S3, consider using DLP solutions on endpoints or proxies for other data egress points. For example, if an attacker tries to use an EC2 as a proxy to download data to their location, a DLP agent or network monitor might catch large file movements. In cloud, this is tricky, but if you route traffic through a central egress, you can at least monitor volume.
User Training and Process: Ensure your team isn’t doing large ad-hoc data copies outside of approved processes. Many breaches involve an insider or attacker masquerading as one doing a “data migration”. If all bulk data transfers are supposed to be approved and scheduled, then any surprise mass reading of data is easier to flag as malicious. This is more of a procedural mitigation, but in smaller organizations especially, making it clear that any unusual data access will be noticed can deter insider malfeasance and make outsider actions pop out.
Exfiltration
Overview:Exfiltration is the phase where an attacker actually transferscollected data out of the AWS environment to an external location undertheir control. In AWS, exfiltration can happen through various channels:downloading data over the Internet (e.g., via AWS CLI to the attacker’smachine), transferring data to an external cloud account (for instance, sharingan S3 bucket or snapshot with the attacker’s AWS account), or using covertchannels like DNS to sneak data out. MITRE’s cloud matrix covers scenarios likeexfiltrating data from cloud storage or leveraging cloud services for exfil. Acommon example is an attacker making an S3 bucket public or generating apresigned URL for sensitive objects and then downloading them from outside.Another example: using an EC2 instance as a proxy to stream data to an externalserver (maybe via HTTPS or an obscure port). Command & Control channelscan double as exfiltration paths if the attacker exfils in small chunks.Essentially, exfiltration in AWS often boils down to large data egressfrom the cloud environment to the outside world.
AWS Services/Logs to Monitor:
VPC Flow Logs – Flow Logs are very useful for detecting exfiltration, especially if the data is sent directly from EC2 instances. They record traffic leaving your VPC. By analyzing Flow Logs, you can identify unusual large egress volumes or connections to unfamiliar external IPs. For example, if a normally quiet instance suddenly has gigabytes of traffic going out to some IP in another country, that’s a sign of possible exfiltration. Flow Logs won’t show content but will show IPs, ports, and byte counts. Coupling this with instance identity (which instance or ENI) helps tie it to earlier stages (maybe that instance was compromised earlier in the kill chain).
CloudTrail – For exfiltration via AWS APIs (like S3), CloudTrail data events again are important. If an attacker directly uses S3 API to download data to outside, those are still GetObject calls in CloudTrail (the difference between Collection and Exfiltration via S3 is subtle - one could say Collection was the reading, Exfiltration is the actual data leaving AWS boundary; but if attacker’s machine is making the API call, the reading was effectively the exfil). Look at GetObject events where the source IP (sourceIPAddress) is external and not recognized (especially if outside your usual geo). CloudTrail also logs if someone generates a Presigned URL (via CreatePresignedURL in some services or as part of S3 access in CloudTrail events indirectly) – if you see that, an attacker might use presigned URLs for exfil so their subsequent downloads won’t show up as CloudTrail events (since CloudTrail logs the creation, not the use of presigned URL). Also monitor CloudTrail for PutObject into unusual locations – exfil could also be the attacker uploading your data to their cloud (e.g., they might do PutObject to a bucket they own in another account). If they configure a Cross-Account destination or do cross-account sharing (like PutBucketPolicy allowing their account access), CloudTrail logs that.
Amazon GuardDuty – GuardDuty has specific findings for exfiltration. Examples: Trojan:EC2/DNSDataExfiltration if data is suspected to be encoded and sent via DNS queries (GuardDuty finding format - Amazon GuardDuty). Or Backdoor:EC2/C&CActivity.B (C2 via DNS or other, which often implies exfil path as well). Also, UnauthorizedAccess:S3/DeliverObjects might indicate someone using S3 as a drop point (though I'm not certain if this exact one exists, GuardDuty does alert on unusual S3 access patterns). The Impact category in GuardDuty includes CryptoCurrency (not exfil, but misuse) and might include if an account is creating resources in an attempt to exfil (like deploying an unfamiliar data exfil tool). At the very least, AnomalousBehaviour or UnauthorizedAccess findings related to network or credentials can tip you off to exfil activity. For example, GuardDuty might not say "exfiltration" explicitly, but a Behavior:EC2/NetworkTrafficVolume anomaly can catch an instance sending significantly more data out than before, which likely is exfil.
AWS CloudFront / AWS Transfer – If by chance an attacker sets up a CloudFront distribution or uses AWS Transfer for SFTP to exfiltrate, those would have logs in CloudFront access logs or Transfer logs (which can be sent to CloudWatch or S3). These are less common, but if you find new CloudFront distributions or strange use of AWS Transfer Family in your account, consider that suspicious.
Detection Strategies:
Data Egress Volume Monitoring: Determine normal egress patterns for your environment (in terms of volume and destination) and then alert on deviations. For instance, if an EC2 instance typically sends out 100MB a day of traffic, but today it sent 5GB, trigger an alert. Use VPC Flow Logs with an analytics tool or Athena: you can aggregate bytes by instance or by IP. Also monitor at the internet gateway level – AWS doesn’t directly give you that, but you could sum all flows with dstAddr not in your IP ranges. If there’s a huge spike, that’s noteworthy. Flow Logs are near-real-time (they can be delivered every 10 minutes), so it's feasible to catch large transfers fairly quickly.
Unusual Destination Addresses: If possible, maintain a list of known good IP ranges (corp offices, partner services, CDN, etc.) and treat exfil to unknown IPs as more suspicious. GuardDuty already uses threat intelligence on IPs (so it will flag known bad ones), but many exfil destinations might be new or not on threat lists. However, if your server suddenly sends data to, say, a residential ISP in Eastern Europe, and you normally only talk to AWS endpoints or CloudFront – that stands out. Tools like Amazon Detective can help trace connections (forensic analysis after detection).
S3 Public/Anonymous Access: If any S3 object is accessed anonymously (without auth) or from an IP not associated with your org, that can indicate exfil if the bucket was made public. AWS CloudTrail data events will show principalId as Anonymous for such access. Set alerts on any anonymous access to private buckets. Also, use the S3 Inventory or Access Analyzer to identify if a bucket becomes public or objects are shared with external accounts (this is more prevention, but also detection if not expected).
CloudTrail Unusual API usage: As mentioned, presigned URLs can bypass logging of actual download. But the creation of them via certain SDK calls might show up (some AWS SDKs logs it in CloudTrail as GetObject with certain params). If you suspect presigned URL use, one strategy is to look at CloudTrail for patterns: if a single GetObject was called with responseElements showing a presigned URL generation (some services like Glacier allow CreatePresignedPost, etc.), then subsequently you see no CloudTrail but data leaked, that fills the gap. This one is complex to catch automatically. Alternatively, if a bucket goes from private to public (someone removed block public access), assume exfil and react.
DNS-based Exfiltration: Attackers sometimes use DNS queries to smuggle data (because DNS can sometimes be overlooked). GuardDuty does detection here by analyzing DNS traffic for patterns of data chunks (like many subdomain queries with encoded data). If you get such a finding (e.g., Backdoor:EC2/DNS.Exfiltration), it means an instance is likely running malware that is exfiltrating data via DNS queries. This is a high-severity event. The detection itself is by GuardDuty using machine learning on DNS logs. So rely on GuardDuty for this, or ensure you have equivalent NIDS solutions.
Respond to Collection Indicators: Ideally, catch exfiltration in the Collection phase or earlier. If you saw a bunch of data being collected and responded (terminated connections, locked accounts) then exfil might be prevented. But if not, double down when you see any sign of exfil – e.g., if GuardDuty flags an EC2 talking to an IP on an unusual port (possible C2), consider isolating that instance immediately before large exfil can occur. Being proactive in earlier phases reduces the chance of reaching full exfiltration.
Mitigation and Best Practices:
Egress Controls: Apply strict egress rules. For example, use an Egress-Only Internet Gateway for IPv6 (blocks inbound, only allows outbound) and tightly control which instances truly need internet access. For others, use NAT gateways with domain whitelisting via proxy or AWS Network Firewall rules to limit where they can send data. If an instance should only call AWS services, give it a VPC endpoint and cut off general internet. This way, even if compromised, it cannot easily exfiltrate data to an arbitrary external server – the connection would be blocked. AWS Network Firewall can also detect anomalies in traffic patterns or block known bad protocols.
Data Loss Prevention (DLP): Incorporate DLP solutions that integrate with AWS. For example, some cloud proxies or CASB solutions can monitor S3 access via APIs and flag downloads of sensitive data. At a simpler level, ensure all sensitive data is encrypted such that even if exfiltrated, it’s not immediately usable (use customer-managed KMS keys and do not store the decrypt key in the same place as data). Then an attacker would have to exfiltrate keys too, which is harder if KMS is well protected.
Responsive Logging: Have a system where a detection (like GuardDuty or unusual flow) triggers an automated response – for example, if >X GB flows out from an instance, automatically quarantine that instance (detach internet gateway or change its security group). AWS CloudWatch and Lambda can facilitate such auto-remediation. It’s risky to automate instance shutdowns, but for critical data, the trade-off might be worth it.
Frequent Drills: Test exfiltration scenarios. See how quickly your team notices if you intentionally transfer a large dummy file from an EC2 to a server you control outside. Time the detection and response. This will highlight gaps in monitoring or overly permissive egress that you can then fix. Also consider testing less obvious channels like DNS or slow trickle exfil to ensure your detection isn’t only volume-based.
Encryption and Key Management: As noted, strong encryption is a mitigation. If all important data is encrypted client-side or with KMS and the attacker doesn’t have key access, exfiltrated data is useless. However, in many cases the attacker will try to get keys (that’s Credential Access phase). Still, robust key management (HSM, splitting roles) can reduce likelihood that exfiltrated data is readable.
Disable Unneeded Services: If you are not using features like S3 presigned URLs or public sharing, consider preventive measures: for instance, use IAM policies to disallow s3:PutObjectAcl that grants public-read, or disallow making snapshots public. AWS Config has rules like “No public EBS snapshots” that you can enforce. By eliminating these exfil vectors, you force attackers to use narrower methods that are easier to catch (e.g., they must transfer through your network where you have monitoring, rather than simply making a snapshot public).
User and Resource Awareness: Know where your sensitive data lives and who/what should legitimately access it. This sounds basic, but without it, you can’t tune your detection or restrictions. For each sensitive data store, have an explicit list of services or accounts that should pull data. If anything outside that list does, treat it as a potential exfil incident until proven otherwise. This mindset ensures a quick reaction to anomalies, limiting data loss.
Command and Control (C2)
Overview:Command and Control refers to the communication channel thatattackers establish to control compromised resources remotely. In AWS, Command& Control often manifests as compromised EC2 instances or containers beaconingout to the attacker’s server, or the attacker using an interactive channelto issue commands in your environment. The C2 could use standard protocols(HTTPS, DNS, SSH) to blend in, or even abuse AWS services (some attackers mightuse an AWS service like IoT or DynamoDB as a makeshift C2 channel to avoidexternal networking). However, more commonly, if malware is planted on an EC2,it will attempt to connect to a malicious host on the Internet to receiveinstructions. From AWS’s perspective, such traffic appears as outbound networkconnections. Another scenario: an attacker might set up their own AWSinfrastructure and have your instance communicate with it (since cloud-to-cloudtraffic might not trigger traditional alarms). The goal of C2 is to maintaincommunication for data exchange, additional instructions (like running morecommands, pivoting, etc.), or to orchestrate multiple compromised assets.
AWS Services/Logs to Monitor:
VPC Flow Logs – Flow Logs are critical for detecting C2 traffic patterns at the network level. Many C2 frameworks use periodic beaconing (e.g., an HTTP request to a certain IP every few minutes). You can look for consistent recurring connections from an instance to a single external IP/port. Flow logs can help identify unusual destination ports (like an instance suddenly making outbound connections to port 4444 or 1337 which are often used by reverse shells). Even if traffic is encrypted, the endpoints and frequency can be clues. If possible, integrate threat intel: known C2 IPs or domains – if any flow in your logs goes to those, raise an alert.
DNS Logs (Route 53 Resolver Query Logs) – Many malware use DNS for C2 (either full data exfil or just as DNS beaconing). By enabling DNS query logging (if you use Route 53 Resolver or running your own DNS logging on servers), you can catch queries to suspicious domains (random subdomains, known bad domains). GuardDuty specifically uses DNS logs for C2 detection and will flag abnormal DNS patterns (GuardDuty finding format - Amazon GuardDuty). For example, “EC2 instance communicating with known malware domain” (GuardDuty has that type of finding under Backdoor or Trojan categories). So, DNS logs are a rich source for C2 detection if analyzed.
Amazon GuardDuty – GuardDuty is a frontline for C2 detection in AWS. It uses threat intelligence and anomaly detection on VPC Flow Logs and DNS logs to identify possible C2 communications. Findings like Backdoor:EC2/C&CActivity.B!DNS mean an EC2 is querying a domain that’s likely a C2 server (GuardDuty finding format - Amazon GuardDuty). Backdoor:EC2/C&CActivity (without DNS) can indicate traffic to known C2 IPs. Trojan:EC2/BlackholeTraffic or Trojan:EC2/DropPoint might indicate known command and control tool signatures in network behavior. Essentially, any GuardDuty finding with C&C or Backdoor is strongly indicative of a C2 channel in your AWS environment and should be addressed immediately.
CloudTrail – CloudTrail might not directly show C2 (as it’s more about API calls), but if the attacker uses something like the AWS API as a control channel, you might catch it. For example, imagine the attacker doesn’t plant external malware but instead uses the AWS API: They could continually invoke Lambda functions or send messages to an SQS queue that compromised resources are checking. This is less common but possible. CloudTrail would log such API usage. Also, if an attacker is manually operating via the AWS Console or CLI to control instances (like using SSM to run commands each time they want to do something), those would be in CloudTrail (SSM SendCommand calls, etc.). That is a kind of “C2” where the attacker themselves is directly controlling via AWS APIs. Monitor for suspicious repetitive actions: e.g., an unknown user issuing frequent SSM commands or starting/stopping instances repeatedly could be an attacker controlling the environment.
Detection Strategies:
GuardDuty C2 Alerts: Simply put, if GuardDuty raises a C2-related finding, treat it as a confirmed incident. These findings have very low false positive rates because they often involve threat intel (like contacting a known bad IP or domain) or highly unusual behavior. For instance, Backdoor:EC2/C&CActivity.B! indicates your EC2 made a DNS request to a domain associated with a known backdoor family (GuardDuty finding format - Amazon GuardDuty). Immediately isolate that instance and begin analysis. Use GuardDuty’s details (it provides domain names, IPs, and sometimes sample payload info) to scope further. Also check if other instances are contacting the same C2 infrastructure.
Beaconing Detection: Use flow logs or a traffic analysis tool to detect beacon-like patterns. Beaconing often means regular, small data connections at a fixed interval. You might not see large volumes, but a consistent pattern like “every 5 minutes this instance connects to 198.x.y.z:443 for a few seconds”. Tools like Zeek (if deployed on traffic mirroring) or SIEM analytics can pick that up. In absence of specialized tools, even CloudWatch metrics on connection counts can hint: for example, if an instance initiates connections at a steady rate regardless of workload, that’s odd.
Strange Ports/Protocols: Many enterprise environments have standardized egress (web traffic on 80/443, DNS on 53, etc). If an instance starts using IRC (port 6667) or SMTP (except if it's a mail server) or other uncommon ports, that’s a clue. Even an HTTPS-based C2 might use a weird port (like 8443 or 10443). Check flow logs for ports that are not commonly used by your applications. Additionally, if an instance that should only talk to AWS services (like S3, DynamoDB) is suddenly making TCP connections to random IPs, you can detect that by comparing flow logs against known AWS IP ranges (AWS publishes IP prefixes; anything outside could be flagged for that instance if it’s supposed to be internal-only).
C2 via Cloud: An advanced attacker might use your own cloud environment for C2 to blend in (e.g., put a message in DynamoDB or SQS that the malware reads via AWS API – that looks like normal AWS API traffic to you). This is very hard to detect via network logs since it’s all internal AWS traffic (to DynamoDB endpoints, etc.), and CloudTrail would just show normal API calls. Detection there would rely on noticing usage of resources that are odd – like if you find an SQS queue you didn’t create (attacker created it to communicate). Or if a normally unused API (like DynamoDB Query from an instance that never used DynamoDB) starts happening regularly. Essentially, this is more of a threat hunt scenario: you’d need to look for odd patterns in usage of services. Not common, but be aware.
Compromise Patterns on Instances: C2 implies the instance is compromised to run the C2 client. Signs of that at instance level include processes or system logs showing unknown programs, high CPU from a process like “xmrig” (crypto miner, which is C2 of sorts but focusing on resource theft), or outbound connections if you have an IDS agent. EDR solutions on cloud VMs are great for catching C2 (they might detect the malware behavior, or suspicious process opening network sockets). So ensure your instances have some endpoint security that can detect known malware or anomalies – those alerts complement cloud-native logs.
Frequency Analysis and Baselines: Use machine learning or statistical baselining on network egress if possible. AWS doesn’t natively do this except GuardDuty’s anomaly detection. If you have a SIEM with UEBA (User and Entity Behavioral Analytics), feed it the VPC Flow data or CloudTrail events. It could flag, for example, that “EC2 instance i-abc123 has started communicating with an IP that no other instance talks to” or “this instance’s outbound traffic volume is 300% higher than usual at regular intervals.” These can reveal stealthy C2 that wouldn’t trigger signature-based alarms.
Example GuardDuty Finding (C2): A concrete example: GuardDuty might generate “Backdoor:EC2/C&CActivity.B”.The details could say: EC2 instance i-1234567890abcdef (Name: WebServer01)in VPC vpc-aaaabbbb is making DNS requests to example.evildomain.xyz. Thisdirectly tells you a C2 domain. You would then check that instance’s Flow Logsto see volume and possibly content if you have packet capture. The key is sucha finding should trigger incident response (isolating the instance, dumpingmemory, etc. if forensics are needed).
Mitigation and Best Practices:
Network Egress Restrictions (again): This is vital for C2 too – if instances cannot initiate arbitrary outbound connections, attackers will struggle to establish C2. Use strategies like only allowing outbound traffic to known update servers or APIs. For workloads that shouldn't call the internet at all, use VPC endpoints for AWS and absolutely no internet gateway. If an attacker can’t reach their server, they can’t control the malware effectively. At least require all egress to go through a proxy where you can do filtering (like restrict by domain or use IDS/IPS).
Threat Intelligence Subscription: Feed threat intel on C2 domains and IPs into your AWS defenses. AWS GuardDuty already has threat intel feeds built-in. You can also add custom threat lists to GuardDuty with IPs you want to be alerted on. If your organization has a known list of bad IPs, put them there so GuardDuty will alert if any traffic hits them (GuardDuty finding format - Amazon GuardDuty). Similarly, update your Network Firewall or security groups with known bad IPs to block if appropriate (though IPs change fast in C2, so threat intel has to be timely).
Timely Patching and Hardening: C2 often comes after an exploit. Keep your EC2 instances patched to reduce the chance that malware can be planted at all. Use security groups to limit open ports (no 0.0.0.0/0 on management ports). If attackers can’t easily get in, they can’t set up C2. Consider using systems like AWS Inspector to identify vulnerable instances and fix them. Many C2 tools exploit known vulnerabilities to get installed. Also remove unnecessary software that might open C2 vectors (e.g., no need for netcat or similar tools on servers typically).
IAM Policies to Prevent Resource Abuse: If you worry about cloud-native C2 (like attacker using your own AWS to control things), set IAM policies such that instances or roles only can use specific services. For example, if your EC2 role should not ever need to use SQS or SNS, deny those in the role’s policy. Then even if attacker tries to use those for C2, they’ll fail. This goes back to least privilege but thinking not just in terms of data access, but any service usage.
Incident Response Plan for C2: Have playbooks ready for isolating C2. For example, if a GuardDuty C2 alert triggers, one play could be: automatically update the security group of that instance to cut off egress (except maybe to trusted IPs or none), attach an isolation role with no privileges (if it’s an IAM compromise case), and notify responders. This containment step is crucial to sever the attacker's control quickly. Practicing it ensures you don't scramble when it happens. AWS SSM can be used to remotely execute an isolation script (provided the attacker hasn't disabled it, which is why quick reaction matters).
Use of AWS SSM Session Manager for your admins: This might sound unrelated, but if your admins always use Session Manager (which logs and goes through AWS API) for instance access, then any direct SSH or weird outbound connections stand out as definitively not normal admin behavior. It's about making the normal pattern distinct, so the abnormal triggers alarms without guesswork.
Monitor for Failed Outbound Attempts: If using egress filtering, monitor the denies. If a compromised instance tries to phone home and is blocked, you'll see flow logs with REJECT or firewall logs. That is an early warning – treat it seriously, don't just silently drop. Those logs should be surfaced to the SOC as potential attempted C2. It's like catching the burglar jiggling the locked door.
Impact
Overview: The Impact tactic encompasses the adversary’s end goals thatdirectly affect the confidentiality, integrity, or availability of the cloudenvironment. In AWS, impact could mean data destruction, service disruption,or resource abuse once the attacker has sufficient access. Common impactsin cloud incidents include:
Data Destruction or Encryption (Ransomware): An attacker might delete data stores (e.g., wipe or encrypt S3 buckets, delete RDS databases or EBS volumes) (GuardDuty finding format - Amazon GuardDuty). They could turn off backups or destroy snapshots to prevent recovery (Persistence, Tactic TA0003 - Enterprise | MITRE ATT&CK®). This could be for ransom (encrypt and demand payment) or pure sabotage.
Service Disruption: Shutting down or disabling critical services – e.g., terminating EC2 instances (causing downtime), altering route tables or security groups to cut off access, or even deleting IAM roles to cause chaos. Also, Denial-of-Service conditions can be created by attackers (though external DoS is mitigated by AWS Shield, an internal actor could spin down services).
Resource Abuse (Crypto-mining): Using your AWS resources for their gain, like launching large EC2 instances to mine cryptocurrency (which costs you money) (GuardDuty finding format - Amazon GuardDuty). This is a different kind of impact (financial impact). GuardDuty categorizes crypto mining under Impact because it’s an adverse effect on your environment (depleted resources) albeit not destructive to data.
Credential or Account Manipulation: Changing account credentials or policies to lock out the legitimate owners (essentially an account takeover). For example, changing root password and MFA, or setting an account-wide deny policy (though AWS has some protections against outright locking root out via SCP, but if they get root they can do a lot). This is impact because it can prevent you from recovering control.
AWS Services/Logs to Monitor:
AWS CloudTrail – CloudTrail will show destructive actions: e.g., DeleteBucket, DeleteObject (for S3 objects), DeleteDBInstance, TerminateInstance, CancelKeyDeletion (for KMS, if they previously scheduled deletion of a KMS key to ensure data encrypted with it becomes irrecoverable). It also logs changes like UpdateBucketVersioning (if attacker disables versioning or turns off MFA Delete, which is a precursor to deleting objects) and PutBucketPolicy if they’re altering access. Essentially, monitor any API calls that indicate deletion or stop of services: TerminateInstances, StopDBInstance, DeleteTrail (to impede logging, which is both defense evasion and impact on IR capability). Also track CreateKey or ScheduleKeyDeletion on KMS – scheduling deletion of KMS keys is a serious impact (after the waiting period, data encrypted becomes irretrievable). CloudTrail is your primary source to catch these actions as they are attempted or executed.
Amazon GuardDuty – GuardDuty’s Impact findings include things like CryptoCurrency mining detection (e.g., CryptoCurrency:EC2/BitcoinTool.X where X is usually an indicator of mining pool traffic) (GuardDuty finding format - Amazon GuardDuty). GuardDuty also might indirectly alert on data destruction if it observes, say, an unusual API call sequence, but primarily it flags symptoms like mining or an account exhibiting policy violations (Policy: category). If an attacker is mass deleting resources via API, GuardDuty might not have a specific finding titled "Data Destruction", but you’ll see the effects in CloudTrail or CloudWatch alarms (and possibly in GuardDuty anomaly of API usage).
AWS Security Hub & Config – Security Hub (with Config) has “Detective Controls” and “Recovery Controls” that align with CIS benchmarks. For example, a Config rule could detect if CloudTrail was disabled or if S3 versioning was disabled (CIS recommends these be on). If an attacker turns them off, those Config rules would flag non-compliance. While not immediate like CloudTrail, they provide another layer of detection for persistent changes that facilitate impact. Security Hub’s Insight or Findings like “Root account used” is relevant because root usage often correlates with high-impact changes (only root can do certain account-level destructions).
Billing Alarms – If the impact is financial (crypto mining or resource sprawl), CloudWatch billing alarms can detect a sudden increase in costs. For instance, if an attacker spins up dozens of GPU instances to mine cryptocurrency, your estimated charges will spike within hours. A Billing Alarm (or AWS Budget alert) for unusual spend is a way to catch this impact within a day or even hours. It's not real-time for security events, but it’s a safety net for the crypto-mining scenario if other detections failed.
CloudWatch Metrics/Alarms on Service Limits: If an attacker tries a destructive event like terminating all instances, you might see CloudWatch alarms if configured for host down or service down. For example, if your web app health checks suddenly all fail because instances were killed, that’s an immediate functional impact – your monitoring system (NewRelic, CloudWatch Alarms on ELB target health) will alert ops, which then can be correlated to security if you discover it was malicious. So operational monitors can double as impact detectors (sudden downtime might be due to attack).
Detection Strategies:
Delete/Modify API Calls: Configure CloudTrail-based alerts for high-impact API calls. Many AWS shops implement AWS Config rules or CloudWatch Events for critical deletes. Examples: Alert when any DeleteBucket or DeleteTrail or DisableAlarm (CloudWatch) or RevokeSecurityGroupIngress (if someone wipes out security group rules unexpectedly) is called. These actions are infrequent in normal ops, so they can often be treated as urgent. The CIS AWS Foundations Benchmark specifically suggests having alarms for IAM policy changes, CloudTrail config changes, etc., which are related (Amazon Web Services Security Control Mappings to MITRE ATT&CK®). You can extend that concept to other destructive actions. Even DetachVolume from an EC2 unexpectedly could be a sign (if attacker is trying to detach and delete volumes).
Resource Deletion Sprees: If an attacker is deleting lots of resources via API or console, you might see a rapid sequence of deletion events. CloudTrail Insights (anomaly detection) might catch the spike in API calls. Or simply a pattern like user X calling DeleteObject 1000 times in a short span (mass deleting S3 objects). Use Logs Insights to count delete API calls by user in short windows. If someone is removing large swaths of data, that should scream. Similarly, TerminateInstance calls for multiple instances in a row. It's rare outside of perhaps an automated scaling down or dev environment cleanup – verify any such sequence.
GuardDuty CryptoMining: If GuardDuty raises a crypto mining finding (Impact:EC2/BitcoinTool), it means an instance is very likely compromised and running miner software (GuardDuty finding format - Amazon GuardDuty). While the immediate impact is cost, it also means that instance was vulnerable enough to install a miner – it could just as easily have been data theft. So treat it as a full incident: investigate how it got there, and also mitigate the cost by terminating the miner. Crypto mining often comes with network traffic to mining pools (GuardDuty detects via DNS or traffic patterns). It's one of the more common cloud attacks in recent years, so having cost alarms and GuardDuty is key.
Account Alterations: Monitor any changes to root account status – e.g., if root’s MFA is disabled (CloudTrail logs DeactivateMFADevice for root), or if access keys appear for root (Security Hub has a finding for root key creation). Those could indicate an attacker preparing to lock you out. Also, if someone calls CreateAccount (in Organizations) unexpectedly, they might be trying to offload resources or just confuse the trail by spawning accounts (not common, but possible). That would be in CloudTrail too.
Ransomware File Patterns: If attacker encrypts files in S3 (like uploading encrypted versions), you might see unusual file additions or changes. Macie could theoretically detect if a bunch of files suddenly become encrypted (gibberish content) though that's advanced. You might have to rely on the fact that they likely will delete backups or change versioning (which you detect) rather than content scanning. For EBS encryption, they'd likely use your KMS keys or their own if they can; hard to detect encryption vs. deletion without context, but either is destructive.
Lockout Signals: If you suddenly cannot access certain resources or get Access Denied for things you used to manage (because attacker changed IAM policies), that's a direct signal. For detection, this might not be automated – the admins notice their API calls failing due to policy changes. CloudTrail would show if someone attached a policy of Deny on everyone. Having a break-glass procedure (and separate account) to regain access is more of a mitigation, but detection-wise, seeing an IAM policy that denies admin actions (like a "": "" deny to all) is clearly malicious. Config or Access Analyzer might catch that as a policy anomaly.
Mitigation and Best Practices:
Backups and Versioning: Ensure that you have backups (and ideally immutable or offline backups) of critical data. Enable S3 Versioning and MFA Delete on important buckets so that even if an attacker deletes objects, you can recover them (and MFA Delete would at least slow them down if they don't have MFA device). Regularly backup RDS databases and have the snapshots copied to a different account. Keep EBS snapshots and ideally copy to offsite. The AWS Backup service can automate cross-account, cross-region backups, which is good because an attacker who compromises one account may not be able to reach backups in another. Test your recovery processes so that if data is destroyed, you can rebuild. This mitigates the impact severity, reducing leverage for ransomware.
Guardrails via SCPs: Use Organizations SCPs to prevent certain destructive actions at the member account level. For example, an SCP that prevents anyone from disabling CloudTrail or deleting Config records. Another could prevent deleting S3 buckets that have certain tags or prevent IAM role modifications on admin roles. SCPs can block even the root user in member accounts from doing those actions (with some exceptions). They are a double-edged sword (misconfigure and you lock yourself out of legitimate actions), but carefully used, they can stop an attacker from performing the most damaging actions. E.g., an SCP could say “Deny DeleteBucket on prod logging bucket” – attacker with prod admin rights still can't nuke the logging bucket.
Least Privilege & Separation of Duties: By now a repeated theme – if no single credential has unrestricted power, then the impact of compromise is limited. Have separate accounts/roles for administration, and everyday roles cannot delete resources or tamper with security settings. Use break-glass accounts (with MFA, tightly controlled) for highly destructive operations. This way, if an attacker compromises a developer's account, they might read data but can’t instantly destroy everything – which gives you time to react. Also consider requiring multiple people for certain deletions (though AWS doesn’t have native two-man rule, you can simulate by having one person remove a preventative control and another execute actual deletion, in a change management sense).
Billing and Budget Alerts: As mentioned, set alerts for sudden cost increases (to catch crypto mining or lots of resource creation). This won't prevent the action but can limit the financial damage by notifying you to shut down instances quickly. AWS Budgets can send email/SNS alerts when spending hits thresholds. There are also services like AWS Cost Anomaly Detection that automatically flags anomalous spend and integrates with CloudWatch. Use these as a net especially for smaller accounts where you might not have 24/7 eyes – a big anomaly likely means either misconfiguration or malicious use.
Penetration Testing and Game Days: Proactively test what impact an attacker could have. Perform simulation: if someone got into account X, could they delete all S3? If yes, adjust permissions or add SCPs until the answer is "they could cause some damage but not wipe us out." Run game days where you simulate an attacker trying to do maximum harm (within a staging environment) and see how your monitors and responders handle it. This can reveal gaps in detection for the Impact stage.
Fast Incident Response: To mitigate Impact, sometimes the best defense is a good offense (detection) earlier. But assuming detection came late, your IR needs to act fast to contain. For example, if you realize an attacker is deleting stuff, you might quickly use whatever access remains to lock the account (maybe call AWS Support to intervene if account takeover). Having emergency contacts with AWS and a plan to “pull the plug” on an AWS account (like migrating critical services out or severing network connections) might be extreme but could stop further damage. AWS Organizations can detach an account’s network by removing SCPs that allow egress if you prepared such an SCP.
Monitoring Post-Change: Even after an attack, keep monitoring because attackers sometimes lay destructive traps (like schedule a Lambda to run in 2 days to re-encrypt data). After regaining control, do a thorough check of all scheduled tasks, new Lambdas, new IAM users, etc., to remove any lingering malicious automation that could re-impact.
Conclusion
In this technical walkthrough, we covered each phase of the MITREATT&CK framework as it applies to AWS cloud environments – from InitialAccess through Impact. By understanding these tactics and the AWS-specifictechniques adversaries might use, defenders can instrument their AWSenvironments for robust monitoring and quick detection. We highlighted how AWSnative services like CloudTrail, GuardDuty, VPC Flow Logs, CloudWatch,Config, and Security Hub can be leveraged to detect suspicious activitiesat each stage.
By leveraging Stream Security, you can effortlessly achieve the above and beyond, ensuring robust protection, real-time threat detection, and seamless security operations. Read more here: Prepare– Detect – Investigate – Respond.
AboutStreamSecurity
Stream.Security delivers the only cloud detection and response solution that SecOps teams can trust. Born in the cloud, Stream’s Cloud Twin solution enables real-time cloud threat and exposure modeling to accelerate response in today’s highly dynamic cloud enterprise environments. By using the Stream Security platform, SecOps teams gain unparalleled visibility and can pinpoint exposures and threats by understanding the past, present, and future of their cloud infrastructure. The AI-assisted platform helps to determine attack paths and blast radius across all elements of the cloud infrastructure to eliminate gaps accelerate MTTR by streamlining investigations, reducing knowledge gaps while maximizing team productivity and limiting burnout.